خوش آموز درخت تو گر بار دانش بگیرد، به زیر آوری چرخ نیلوفری را
آموزش نصب Hadoop در اوبونتو

هر صنعت بزرگی Apache Hadoop را به عنوان framework استاندارد به منظور پردازش و ذخیره داده های بزرگ پیاده سازی می کند. Hadoop به گونه ای طراحی شده است که در شبکه ای متشکل از صدها یا حتی هزاران سرور اختصاصی مستقر شود. همه این ماشین ها با هم کار می کنند تا با حجم عظیم و گوناگون مجموعه داده های ورودی تقابل داشته باشند.

مستقر کردن Hadoop روی یک node راه بسیار خوبی برای آشنایی با دستورات و مفاهیم اولیه و پایه ای Hadoop است.
در اصل هدف ما همانطور که در موضوع مقاله هم مشخص است، نصب کردن Hadoop در اوبونتو 18.04 یا اوبونتو 20.04 است.
Hadoop framework به زبان جاوا برنامه نویسی شده است و سرویسش به یک JRE و JDK نیاز دارد. قبل از شروع نصب، از دستور زیر برای آپدیت سیستم خود استفاده کنید:
در حال حاضر Apache Hadoop 3.x به طور کامل از جاوا 8 پشتیبانی می کند. پکیج OpenJDK 8 در اوبونتو که شامل runtime environment و development kit است را با دستور زیر می توانید نصب کنید:
پس از اتمام کار با اجرای دستور زیر می توانید ورژن جاوای نصب شده را مشاهده کنید که تاییدی بر نصب می باشد:
خروجی به شما اطلاع می دهد که کدام نسخه جاوا در حال استفاده است.

به منظور نصب OpenSSH server و OpenSSH client می توانید از دستور زیر استفاده کنید:
در مثال زیر، خروجی تایید می کند که آخرین نسخه از قبل نصب شده است.

حالا از دستور adduser برای ایجاد یک کاربر Hadoop استفاده کنید.
در مثال فوق، نام کاربری hdoop تنظیم شده است که شما می توانید هر نام دیگری را به جای آن قرار دهید.
سپس با دستور زیر با کاربری که هم اکنون ایجاد کردید به خط فرمان دسترسی پیدا خواهید کرد. در واقع به نوعی سوئیچ می کنید. نام کاربر خودتان را جایگزین کنید:
کاربر اکنون باید بتواند بدون درخواست پسورد به localhost ارتباط SSH برقرار کند.
سیستم اقدام به تولید و ذخیره جفت کلید SSH می کند.
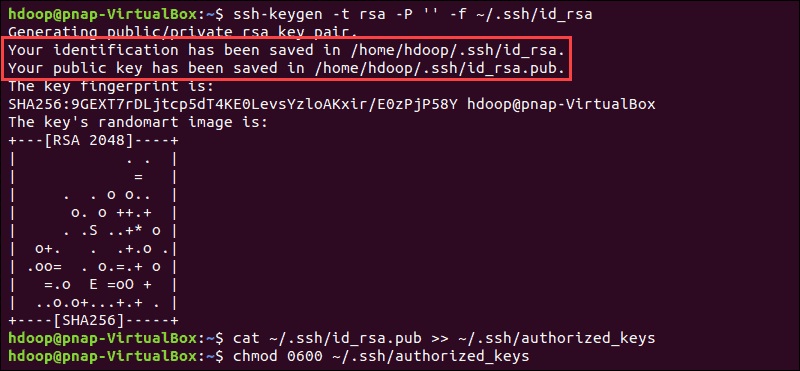
از دستور cat برای ذخیره public key به عنوان autorized_keys در دایرکتوری ssh استفاده کنید:
با دستور chmod مجوزها را برای کاربر خود تنظیم کنید:
کاربر جدید اکنون میتواند بدون نیاز به وارد کردن رمز عبور، ارتباط SSH را برقرار کند. با استفاده از کاربر hdoop در SSH به لوکال هاست، تأیید کنید که همه چیز به درستی تنظیم شده است:
پس از درخواست اولیه، کاربر Hadoop اکنون میتواند یک اتصال SSH به localhost را به طور یکپارچه برقرار کند.
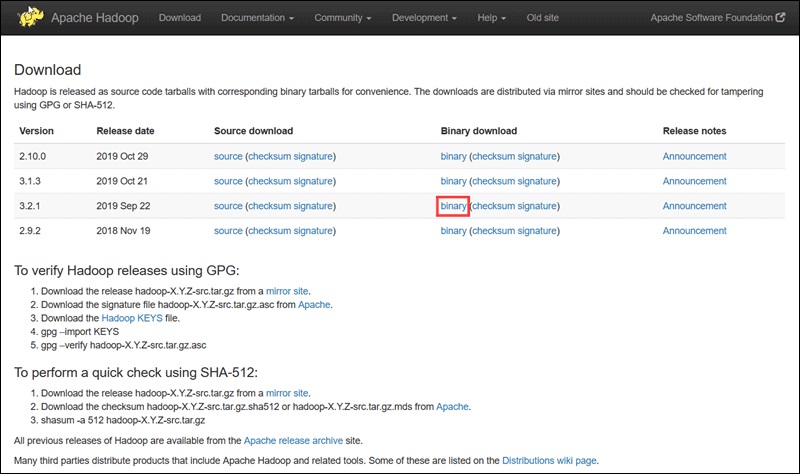
همانطور که مشاهده می کنید، نسخه Hadoop Version 3.2.1 ورژن مورد نظر برای دانلود است.
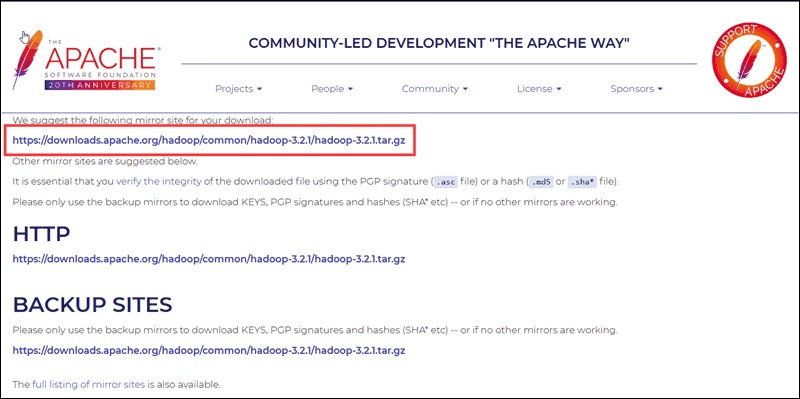
سپس به صفحه دیگری خواهید رفت. در این صفحه، پکیج tar برنامه Hadoop را می توانید دانلود کنید.
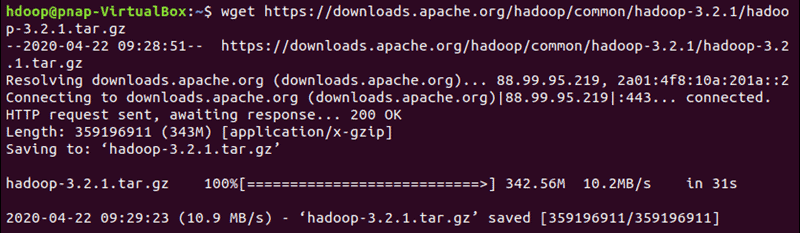
از دستور wget برای دانلود پکیج Hadoop می توانید استفاده کنید. کافیست لینک را پس از دستور در خط فرمان وارد کنید:
پس از اتمام دانلود، فایل ها را برای شروع نصب Hadoop استخراج یا Extract کنید:
فایل های باینری Hadoop اکنون در دایرکتوری hadoop-3.2.1 قرار دارند.
environment variable ها یا متغیرهای محیطی Hadoop را با افزودن محتوای زیر به انتهای فایل تعریف کنید(فقط به شماره ورژن ها دقت کنید):
زمانی که variable ها را اضافه کردید، فایل را ذخیره و خارج شوید.
اعمال تغییرات در محیط در حال اجرا با استفاده از دستور زیر ضروری است:
متغیر JAVA_HOME$ را از حالت comment خارج کنید(باید علامت # قبل از آن را حذف کنید). و مسیر کامل را به نصب OpenJDK در سیستم خود اضافه کنید. اگر همان نسخه ارائه شده در قسمت اول این آموزش را نصب کرده اید، خط زیر را اضافه کنید:
مسیر باید با محل نصب جاوا در سیستم شما مطابقت داشته باشد.
اگر برای یافتن مسیر صحیح جاوا به کمک نیاز دارید، دستور زیر را در پنجره ترمینال اجرا کنید:
خروجی مسیر دایرکتوری باینری جاوا را نشان می دهد:

از مسیر ارائه شده برای یافتن دایرکتوری OpenJDK با دستور زیر استفاده کنید:
بخشی از مسیر درست قبل از فولدر /bin/javac باید به متغیر JAVA_HOME$ اختصاص داده شود.

پیکربندی زیر را اضافه کنید تا مقادیر پیشفرض دایرکتوری موقت را کنسل کنید و URL HDFS خود را برای جایگزینی تنظیمات پیشفرض فایل سیستم لوکال اضافه کنید(فایل را از اینجا می توانید دانلود کنید):
این مثال از مقادیر خاص لوکالِ یسیستم استفاده می کند. شما باید از مقادیری استفاده کنید که با نیازهای سیستم شما مطابقت داشته باشد. داده ها باید در طول فرآیند پیکربندی سازگار باشند.
فراموش نکنید که یک دایرکتوری لینوکس در مکانی که برای داده های موقت خود مشخص کرده اید ایجاد کنید.
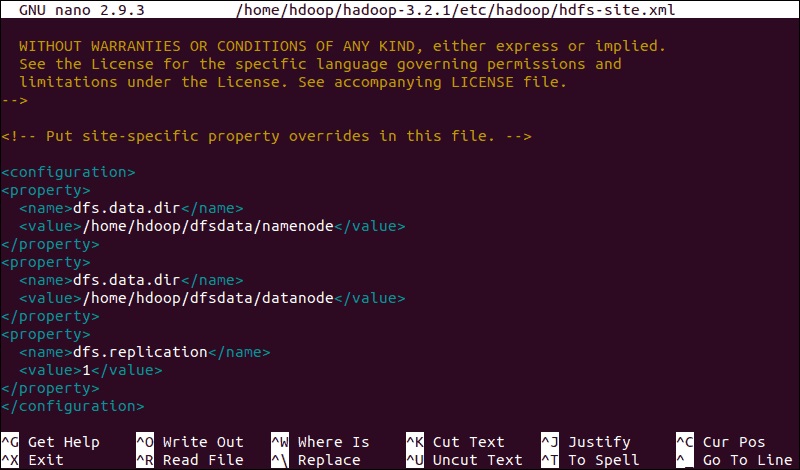
علاوه بر این، مقدار پیشفرض dfs.replication 3 باید به 1 تغییر یابد تا با تنظیمات node منطبق شود. از دستور زیر برای باز کردن فایل hdfs-site.xml برای ویرایش استفاده کنید:
پیکربندی زیر را به فایل اضافه کنید و در صورت نیاز، دایرکتوری های NameNode و DataNode را در مکان های سفارشی خود تنظیم کنید(تنظیمات شکل زیر را از اینجا می توانید دانلود کنید):
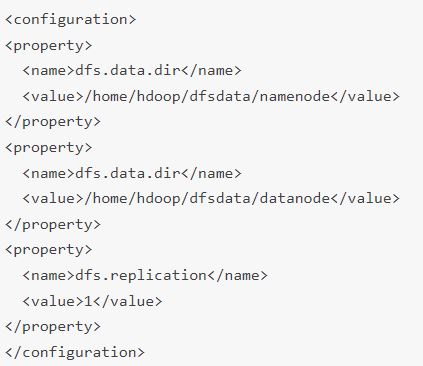
در صورت لزوم، دایرکتوری های خاصی را که برای مقدار dfs.data.dir تعریف کرده اید ایجاد کنید.
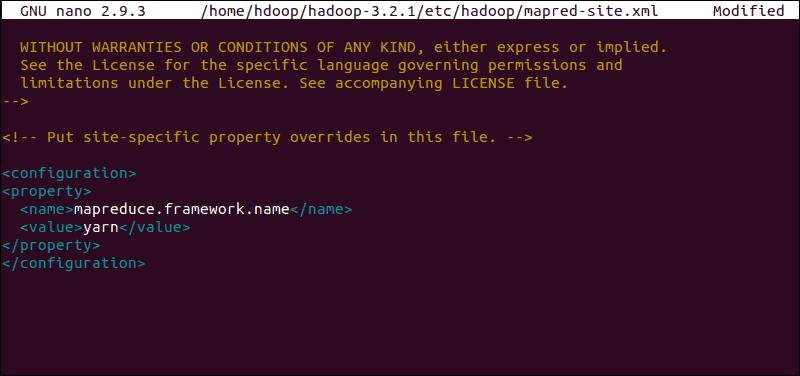
پیکربندی زیر را برای تغییر مقدار نام فریمورک پیشفرض MapReduce به yarn اضافه کنید(تنظیمات زیر را از اینجا می توانید دانلود کنید):

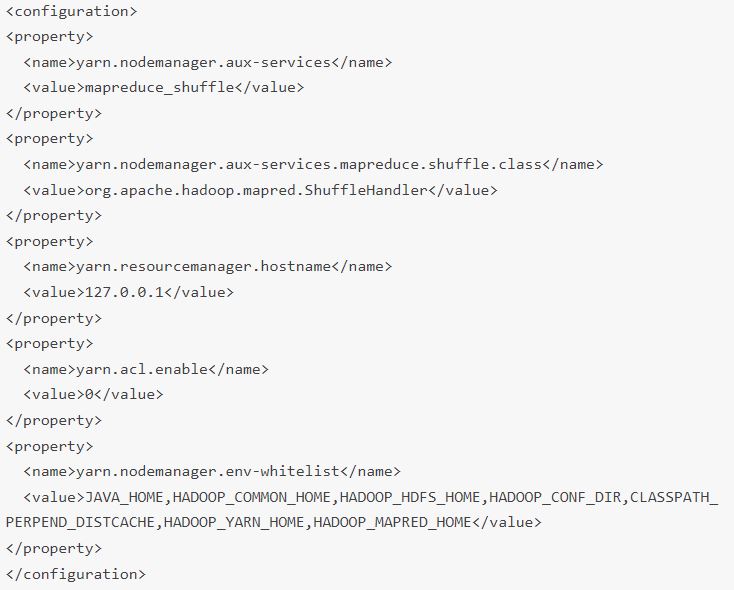
پس فایل yarn-site.xml را باز کنید:
تنظیمات زیر را به فایل اضافه کنید(تنظیمات را اینجا می توانید دانلود کنید):
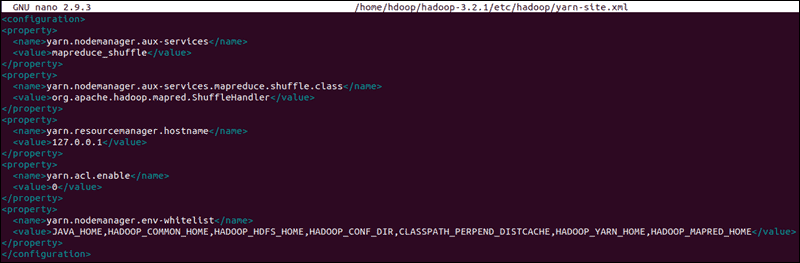
اعلان shutdown نشان دهنده پایان فرآیند فرمت NameNode است.
سیستم چند لحظه ای طول می کشد تا node های لازم را راه اندازی کند.

پس از راهاندازی و اجرای namenode، datanode و namenode ثانویه، YARN و nodemanagers را با تایپ کردن دستور زیر اجرا کنید:
مانند دستور قبلی، خروجی به شما اطلاع می دهد که فرآیندها استارت شده اند.
پورت پیشفرض 9864 برای دسترسی مستقیم به DataNodeهای جداگانه از مرورگر شما استفاده میشود:
YARN Resource Manager در شماره پورت 8088 قابل دسترسی می باشد:
Resource Manager ابزاری ارزشمند است که به شما امکان می دهد تمام فرآیندهای در حال اجرا در کلاستر Hadoop خود را مانیتور کنید.

مستقر کردن Hadoop روی یک node راه بسیار خوبی برای آشنایی با دستورات و مفاهیم اولیه و پایه ای Hadoop است.
در اصل هدف ما همانطور که در موضوع مقاله هم مشخص است، نصب کردن Hadoop در اوبونتو 18.04 یا اوبونتو 20.04 است.
Hadoop framework به زبان جاوا برنامه نویسی شده است و سرویسش به یک JRE و JDK نیاز دارد. قبل از شروع نصب، از دستور زیر برای آپدیت سیستم خود استفاده کنید:
sudo apt update
در حال حاضر Apache Hadoop 3.x به طور کامل از جاوا 8 پشتیبانی می کند. پکیج OpenJDK 8 در اوبونتو که شامل runtime environment و development kit است را با دستور زیر می توانید نصب کنید:
sudo apt install openjdk-8-jdk -y
پس از اتمام کار با اجرای دستور زیر می توانید ورژن جاوای نصب شده را مشاهده کنید که تاییدی بر نصب می باشد:
java -version; javac -version
خروجی به شما اطلاع می دهد که کدام نسخه جاوا در حال استفاده است.
تنظیم یک کاربر غیر Root برای محیط Hadoop
توصیه می شود ک هبرای محیط Hadoop یک کاربر غیر root ایجاد کنید. یک کاربر متمایز امنیت را بهبود میبخشد و به شما کمک میکند تا Cluster خود را کارآمدتر مدیریت کنید. برای اطمینان از عملکرد روان سرویس های Hadoop، کاربر باید توانایی ایجاد یک اتصال SSH بدون رمز عبور با localhost را داشته باشد.به منظور نصب OpenSSH server و OpenSSH client می توانید از دستور زیر استفاده کنید:
sudo apt install openssh-server openssh-client -y
در مثال زیر، خروجی تایید می کند که آخرین نسخه از قبل نصب شده است.
حالا از دستور adduser برای ایجاد یک کاربر Hadoop استفاده کنید.
sudo adduser hdoop
در مثال فوق، نام کاربری hdoop تنظیم شده است که شما می توانید هر نام دیگری را به جای آن قرار دهید.
سپس با دستور زیر با کاربری که هم اکنون ایجاد کردید به خط فرمان دسترسی پیدا خواهید کرد. در واقع به نوعی سوئیچ می کنید. نام کاربر خودتان را جایگزین کنید:
su - hdoop
کاربر اکنون باید بتواند بدون درخواست پسورد به localhost ارتباط SSH برقرار کند.
فعال کردن SSH بدون پسورد برای کاربر Hadoop
یک جفت کلید SSH ایجاد کنید و مکانی که باید در آن ذخیره شود را مشخص کنید:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
سیستم اقدام به تولید و ذخیره جفت کلید SSH می کند.
از دستور cat برای ذخیره public key به عنوان autorized_keys در دایرکتوری ssh استفاده کنید:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
با دستور chmod مجوزها را برای کاربر خود تنظیم کنید:
chmod 0600 ~/.ssh/authorized_keys
کاربر جدید اکنون میتواند بدون نیاز به وارد کردن رمز عبور، ارتباط SSH را برقرار کند. با استفاده از کاربر hdoop در SSH به لوکال هاست، تأیید کنید که همه چیز به درستی تنظیم شده است:
ssh localhost
پس از درخواست اولیه، کاربر Hadoop اکنون میتواند یک اتصال SSH به localhost را به طور یکپارچه برقرار کند.
Download and Install Hadoop on Ubuntu
به صفحه دانلود Hadoop بروید. سپس به سراغ ورژن Hadoop تان که می خواهید دانلود و نصب کنید، بروید.
همانطور که مشاهده می کنید، نسخه Hadoop Version 3.2.1 ورژن مورد نظر برای دانلود است.
سپس به صفحه دیگری خواهید رفت. در این صفحه، پکیج tar برنامه Hadoop را می توانید دانلود کنید.
از دستور wget برای دانلود پکیج Hadoop می توانید استفاده کنید. کافیست لینک را پس از دستور در خط فرمان وارد کنید:
wget https://downloads.apache.org/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
پس از اتمام دانلود، فایل ها را برای شروع نصب Hadoop استخراج یا Extract کنید:
tar xzf hadoop-3.2.1.tar.gz
فایل های باینری Hadoop اکنون در دایرکتوری hadoop-3.2.1 قرار دارند.
Single Node Hadoop Deployment (Pseudo-Distributed Mode)
Hadoop زمانی که در حالت کاملاً توزیع شده روی یک کلاستر بزرگ از سرورهای شبکه مستقر شود، برتری می یابد. با این حال، اگر در Hadoop تازه کار هستید و میخواهید دستورات اولیه یا برنامههای آزمایشی را بررسی کنید، میتوانید Hadoop را روی یک سیستم پیکربندی کنید. این نوع راه اندازی، حالت pseudo-distributed mode هم نامیده می شود. محیط Hadoop با ویرایش مجموعه ای از configuration file ها پیکربندی می شود:bashrc
hadoop-env.sh
core-site.xml
hdfs-site.xml
mapred-site-xml
yarn-site.xml
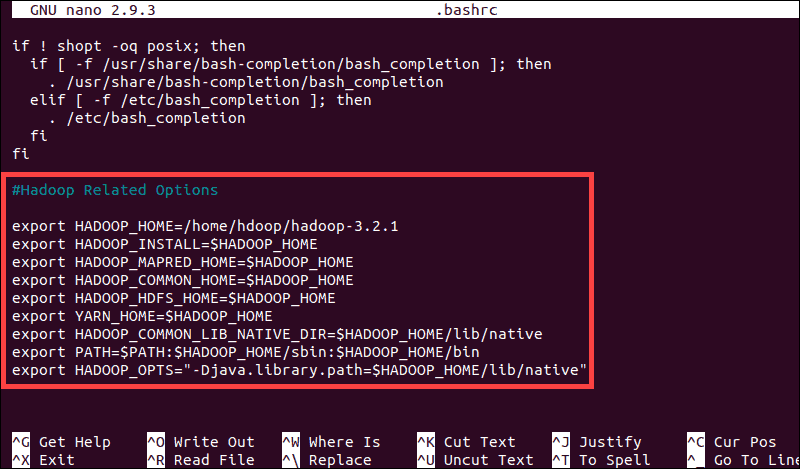
Configure Hadoop Environment Variables (bashrc)
فایل پیکربندی شل bashrc را با استفاده از ویرایشگر متن مورد نظرتان ویرایش کنید (ما از nano استفاده خواهیم کرد):sudo nano .bashrc
environment variable ها یا متغیرهای محیطی Hadoop را با افزودن محتوای زیر به انتهای فایل تعریف کنید(فقط به شماره ورژن ها دقت کنید):
#Hadoop Related Options
export HADOOP_HOME=/home/hdoop/hadoop-3.2.1
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS"-Djava.library.path=$HADOOP_HOME/lib/nativ"
زمانی که variable ها را اضافه کردید، فایل را ذخیره و خارج شوید.
اعمال تغییرات در محیط در حال اجرا با استفاده از دستور زیر ضروری است:
source ~/.bashrc
Edit hadoop-env.sh File
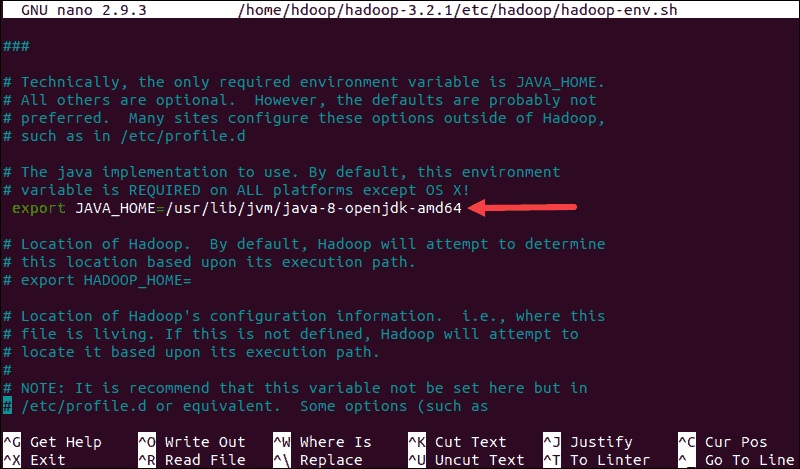
فایل hadoop-env.sh به عنوان یک فایل اصلی برای پیکربندی تنظیمات پروژه مربوط به YARN، HDFS، MapReduce و Hadoop عمل می کند. هنگام راه اندازی یک node تکی از کلاستر Hadoop باید مشخص کنید که از کدام پیاده سازی جاوا استفاده شود. برای دسترسی به فایل hadoop-env.sh از متغیر $HADOOP_HOME قبلا ایجاد شده استفاده کنید:sudo nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
متغیر JAVA_HOME$ را از حالت comment خارج کنید(باید علامت # قبل از آن را حذف کنید). و مسیر کامل را به نصب OpenJDK در سیستم خود اضافه کنید. اگر همان نسخه ارائه شده در قسمت اول این آموزش را نصب کرده اید، خط زیر را اضافه کنید:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
مسیر باید با محل نصب جاوا در سیستم شما مطابقت داشته باشد.
اگر برای یافتن مسیر صحیح جاوا به کمک نیاز دارید، دستور زیر را در پنجره ترمینال اجرا کنید:
which javac
خروجی مسیر دایرکتوری باینری جاوا را نشان می دهد:
از مسیر ارائه شده برای یافتن دایرکتوری OpenJDK با دستور زیر استفاده کنید:
readlink -f /usr/bin/javac
بخشی از مسیر درست قبل از فولدر /bin/javac باید به متغیر JAVA_HOME$ اختصاص داده شود.
Edit core-site.xml File
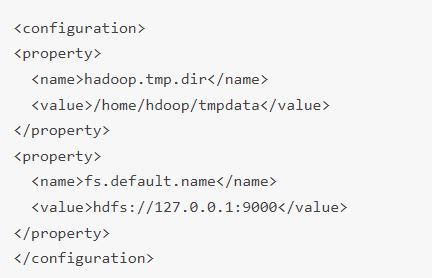
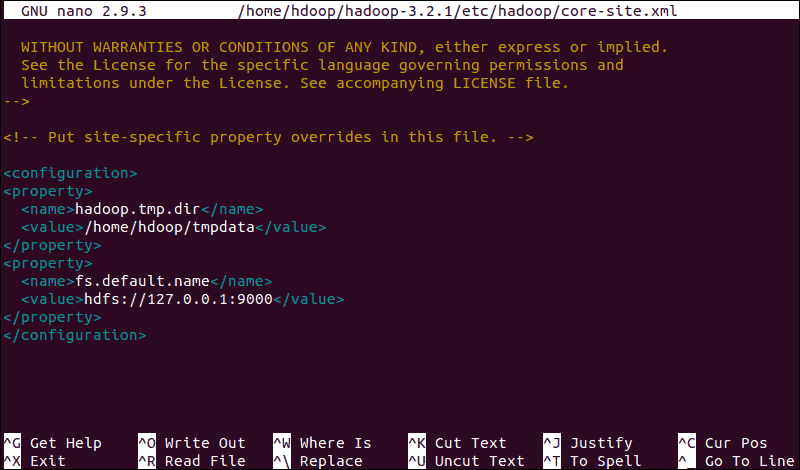
فایل core-site.xml ویژگی های هسته HDFS و Hadoop را تعریف می کند. برای راه اندازی Hadoop در حالت pseudo-distributed mode باید URL را برای NameNode خود و دایرکتوری موقتی که Hadoop برای map و کاهش process استفاده می کند را مشخص کنید. فایل core-site.xml را در یک ویرایشگر متن باز کنید:sudo nano $HADOOP_HOME/etc/hadoop/core-site.xml
پیکربندی زیر را اضافه کنید تا مقادیر پیشفرض دایرکتوری موقت را کنسل کنید و URL HDFS خود را برای جایگزینی تنظیمات پیشفرض فایل سیستم لوکال اضافه کنید(فایل را از اینجا می توانید دانلود کنید):
این مثال از مقادیر خاص لوکالِ یسیستم استفاده می کند. شما باید از مقادیری استفاده کنید که با نیازهای سیستم شما مطابقت داشته باشد. داده ها باید در طول فرآیند پیکربندی سازگار باشند.
فراموش نکنید که یک دایرکتوری لینوکس در مکانی که برای داده های موقت خود مشخص کرده اید ایجاد کنید.
Edit hdfs-site.xml File
ویژگیهای موجود در فایل hdfs-site.xml بر مکان ذخیرهسازی متادیتای node، فایل fsimage و فایل لاگ ویرایش کنترل دارد. فایل را با تعریف دایرکتوری های ذخیره سازی NameNode و DataNode پیکربندی کنید.علاوه بر این، مقدار پیشفرض dfs.replication 3 باید به 1 تغییر یابد تا با تنظیمات node منطبق شود. از دستور زیر برای باز کردن فایل hdfs-site.xml برای ویرایش استفاده کنید:
sudo nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml
پیکربندی زیر را به فایل اضافه کنید و در صورت نیاز، دایرکتوری های NameNode و DataNode را در مکان های سفارشی خود تنظیم کنید(تنظیمات شکل زیر را از اینجا می توانید دانلود کنید):
در صورت لزوم، دایرکتوری های خاصی را که برای مقدار dfs.data.dir تعریف کرده اید ایجاد کنید.
Edit mapred-site.xml File
برای دسترسی به فایل mapred-site.xml و تعریف مقادیر MapReduce از دستور زیر استفاده کنید:sudo nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
پیکربندی زیر را برای تغییر مقدار نام فریمورک پیشفرض MapReduce به yarn اضافه کنید(تنظیمات زیر را از اینجا می توانید دانلود کنید):
Edit yarn-site.xml File
فایل yarn-site.xml برای تعریف تنظیمات مربوط به YARN استفاده می شود که شامل تنظیماتی برای Node Manager، Resource Manager، Containers و Application Master است.پس فایل yarn-site.xml را باز کنید:
sudo nano $HADOOP_HOME/etc/hadoop/yarn-site.xml
تنظیمات زیر را به فایل اضافه کنید(تنظیمات را اینجا می توانید دانلود کنید):
Format HDFS NameNode
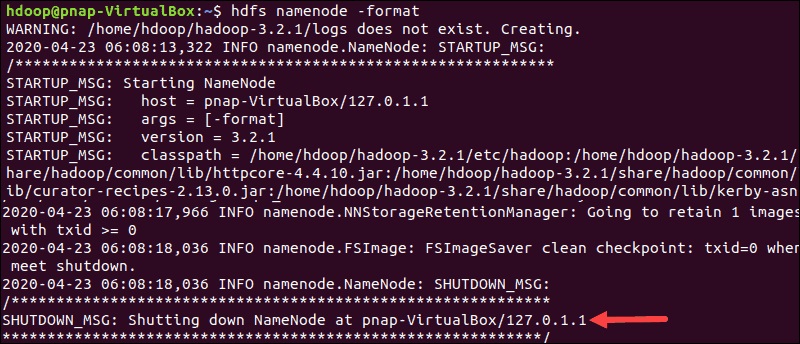
فرمت NameNode قبل از استارت سرویس Hadoop در بار نخست بسیار مهم است:hdfs namenode -format
اعلان shutdown نشان دهنده پایان فرآیند فرمت NameNode است.
Start Hadoop Cluster
به دایرکتوری hadoop-3.2.1/sbin بروید و دستورات زیر را برای استارت NameNode و DataNode اجرا کنید:./start-dfs.sh
سیستم چند لحظه ای طول می کشد تا node های لازم را راه اندازی کند.
پس از راهاندازی و اجرای namenode، datanode و namenode ثانویه، YARN و nodemanagers را با تایپ کردن دستور زیر اجرا کنید:
./start-yarn.sh
مانند دستور قبلی، خروجی به شما اطلاع می دهد که فرآیندها استارت شده اند.
Access Hadoop UI from Browser
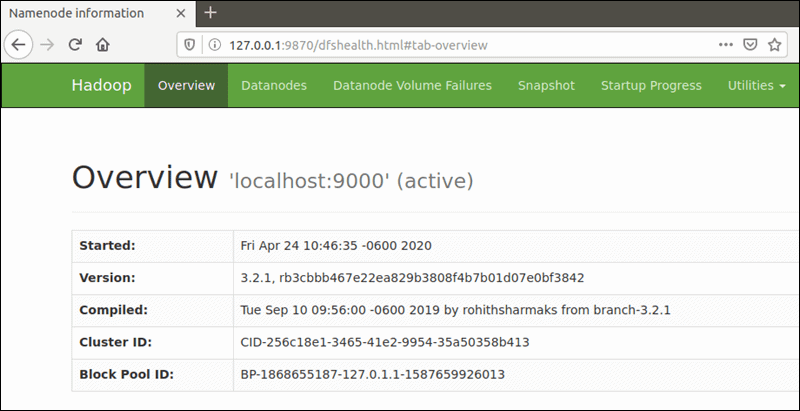
از مرورگر دلخواه خود استفاده کنید و به URL یا IP سیستم لوکال تان بروید. شماره پورت پیش فرض 9870 به شما امکان دسترسی به رابط کاربری Hadoop NameNode را می دهد:http://localhost:9870
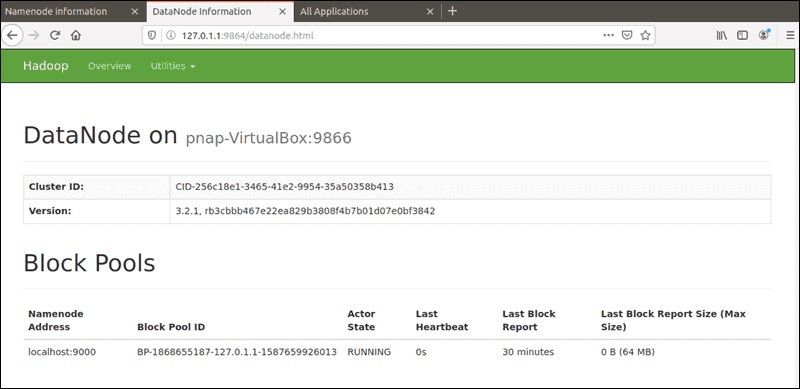
پورت پیشفرض 9864 برای دسترسی مستقیم به DataNodeهای جداگانه از مرورگر شما استفاده میشود:
http://localhost:9864
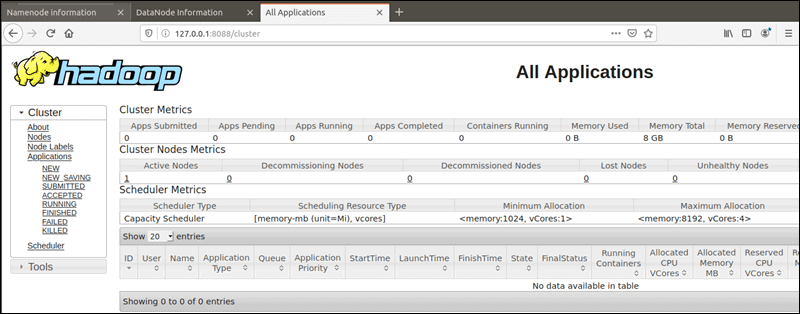
YARN Resource Manager در شماره پورت 8088 قابل دسترسی می باشد:
http://localhost:8088
Resource Manager ابزاری ارزشمند است که به شما امکان می دهد تمام فرآیندهای در حال اجرا در کلاستر Hadoop خود را مانیتور کنید.


دسته بندی مطالب خوش آموز

نمایش دیدگاه ها (0 دیدگاه)
دیدگاه خود را ثبت کنید: