خوش آموز درخت تو گر بار دانش بگیرد، به زیر آوری چرخ نیلوفری را
متریک های مهم برای مانیتورینگ محیط vmware vsphere



به جای استفاده از یک سرور فیزیکی برای هر اپلیکیشنی که اجرا می کنید، مجازی سازی شما را قادر می سازد منابع یک سرور را در چندین ماشین مجازی پخش دهید تا بتوانید چندین سیستم عامل مجزا را داشته باشید که workload های متفاوتی را بر روی یک ماشین اجرا می کنند و امکان استفاده کارآمدتر از منابع فیزیکی مشابه و کاهش هزینه برای فضای ذخیره سازی و نگهداری سخت افزار را فراهم می کند.
VMware همچنین ابزارهای مدیریت cluster مانندDistributed Resource Scheduler یا DRS را ارائه می دهد که از vMotion برای توزیع خودکار منابع فیزیکی مشترک بین VM ها بر اساس نیاز آنها استفاده می کند. در مواردی که برای سرور خاصی انتظار downtime وجود دارد(مثلا برای maintenance)، یا روی سرور بار بیش از حد قرار دارد و Load سرور بسیار سنگین شده، به سادگی و با کمک Vmotion می توانیم ماشین مجازی را بدون هیچ downtime ای از یک سرور به سرور دیگر انتقال دهیم. DRS و vMotion دو کامپوننت جدا هستند ولی در کنار هم کار می کنند تا محیط مجازی شما را انعطافپذیر کنند.
اگر سازمان شما از vSphere برای اجرای اپلیکیشن ها استفاده میکند، بسیار مهم است که به performance و ظرفیت کلی محیط خود در لایههای مختلف، از جمله VM های در حال اجرا و هاست ها، توجه کافی داشته باشید. بدین ترتیب اطمینان حاصل می شود که منابع موجود نیازهای اپلیکیشن ها و سرویس های در حال اجرا در زیرساخت vSphere شما را برآورده می کند.
Performance و ظرفیت دست در دست هم دارند. به عنوان مثال، اگر اپلیکیشن ها و workload های شما با bottleneck مواجه شوند، اگر ظرفیت منابع لازم را نداشته باشید، می تواند منجر به کاهش performance یا حتی downtime شود. برای ادمین های vSphere، مانیتورینگ میتواند به اصلاح vm ها کمک کند تا منابع به طور بهینه بین آنها توزیع شود. مانیتورینگ vSphere به شما کمک میکند تا اطمینان حاصل کنید که اپلیکیشن های اجرا شده روی vm ها مطابق انتظار عمل میکنند.
در این مطلب ما متریک های کلیدی را پوشش می دهیم که دید و اطلاع در مورد سلامت، performance و ظرفیت زیرساخت vSphere شما ارائه می دهد. این شامل متریک هایی از هر دو کامپوننت زیرساخت فیزیکی و مجازی vSphere است که به دستههای زیر تقسیم میشود:
Summary metrics
CPU metrics
Memory metrics
Disk metrics
Network metrics
پیش از پرداختن به این متریک ها، بیایید به نحوه کار vSphere نگاه کنیم. VSphere از مجموعه ای از کامپوننت ها تشکیل شده که پلت فرم مجازی سازی آن را تشکیل می دهند. به منظور مانیتورینگ، دو کامپوننت اصلی وجود دارد که باید از آنها اطلاع داشته باشید:
ESXi hypervisors
the vCenter Server
ESXi hypervisors
ESXI یک bare-metal hypervisor است روی سرورهای فیزیکی مانند سیستم عامل نصب می شود و روی آن می توان ماشین های مجازی را نصب و کنترل کرد. کرنل esxi همانطور که می دانید VMKernel نام دارد. VMKernel مسئول جداسازی منابع از سرورهای فیزیکی است که هایپروایزر ESXi روی آنها نصب شده است و این منابع را در اختیار ماشین های مجازی قرار می دهد.سروری که ESXi روی آن نصب شده، ESXi Host نام دارد. بهطور پیشفرض، ESXi Host ها منابع فیزیکی را به هر vm در حال اجرا بر اساس عوامل مختلفی، از جمله منابع موجود (روی یک هاست یا گروهی از هاست ها)، تعداد vm های در حال اجرا، و منابع مصرفی آن vm ها اختصاص میدهند. اگر منابع overcommit شوند(تخصیص منابع از ظرفیت کل فراتر رود)، سه settings ای که توسط آنها می توانید مدیریت و بهینه سازی نحوه تخصیص منابع را در هاست esxi سفارشی کنید، به شرح ذیل می باشد:
Shares
: بنا بر یک شاخصی شما می توانید استفاده از منابع توسط VM ای را نسبت به vm های دیگر ارجح کنید. اگر نسبت share یک vm نسبت به سارین بالاتر باشد مثلا می تواند مموری بیشتری را در اختیار داشته باشد و Consume کند.Reservation
: حداقل مقدار منبع است که برای Resource Pool، Vapp و یا خودِ VM تضمین و گارانتی می کنیم. مثلا برای یک vm مقدار 2048 مگابیت رم را reserve می کنیم.Limit
: حداکثر مقدار منبعی را که هاست ESXi به یک ماشین مجازی، vApp، Resource Pool تخصیص می دهد، تعیین می کند.بهطور پیشفرض، ماشینهای مجازی بر اساس منابع تخصیصیافته، دارای shares خواهند بود. به عبارت دیگر، اگر به یک ماشین مجازی دو برابر VM دیگر VCPU اختصاص داده شود، دو برابر بیشتر CPU share خواهد داشت. Share به هر گونه رزرو یا limit پیکربندی شده محدود می شود، بنابراین حتی اگر یک ماشین مجازی Share بیشتری داشته باشد، هاست منابع بیشتری از حد تعیین شده خود اختصاص نخواهد داد.
همچنین می توانید منابع فیزیکی یک یا چند هاست ESXi را به واحدهای منطقی به نام Resource Pool تقسیم کنید. Resource pool ها به صورت سلسله مراتبی سازماندهی می شوند. یک parent pool می تواند شامل تعدادی vm باشد و یا resource poll های دیگری درون آن ایجاد شوند. pool ها منابع انعطافپذیری را به مدیریت منابع vSphere اضافه میکنند و مصرف منابع را در سراسر سازمان شما ممکن میسازد(اگر دوره vcp را گذرانده باشید حتما به این مباحث اشراف دارید).
vCenter Server
Vcenter Server چیست و آیا به وجود Vcenter در سازمان ها نیاز است؟
Inventory Object ها در vcenter vsphere
vCenter Server یک کامپوننت از vmware vsphere که به منظور مدیریت متمرکز هاست esxi می تواند استفاده شود. از طریق vCenter، مدیران vSphere می توانند سلامت و وضعیت همه هاست های ESXi متصل را کنترل کنند. vCenter همچنین یک ابزار متمرکز برا پیکربندی و مانیتورینگ ماشین های مجازی در هاست های ESXi مدیریتشان می کند ارائه می دهد. هاست های ESXi که توسط یک vCenter مدیریت می شوند را می توان در Cluster ها گروه بندی کرد.
ماشین های مجازی که روی هاست هایی در یک کلاستر اجرا می شوند، منابعی را بین خوشان از جمله، CPU، حافظه، فضای ذخیره سازی و پهنای باند شبکه را به اشتراک می گذارند.
Vcenter را در ورژن 6.5 و ورژن های قبل تر را می توانستیم روی ویندوز سرور هم نصب کنیم ولی از ورژن 6.7 به بعد دیگر این امر شدنی نیست و فقط نسخه Appliance آن را روی esxi می توان deploy کرد که به دو روش هم از طریق خط فرمان و هم از طریق کنسول وب می توان آن را انجام داد.
نحوه نصب و پیکربندی Vcenter Server 6.7 در VMWare Workstation - بخش اول
نحوه نصب و پیکربندی Vcenter Server 6.7 در VMWare Workstation - بخش دوم
و و اقعا نسخه Vcenter Appliance قابل اعتمادتر است چرا که به ویندوز و سیستم عاملی وابسته نیست. تصویر زیر یک Cluster از یک datacenter را نشان می دهد. این Cluster از سه هاست ESXi تشکیل شده است که هر کدام دو ماشین مجازی (شامل vCenter) هستند که اپلیکیشن ها و سیستم عامل مهمان خود را اجرا می کنند.
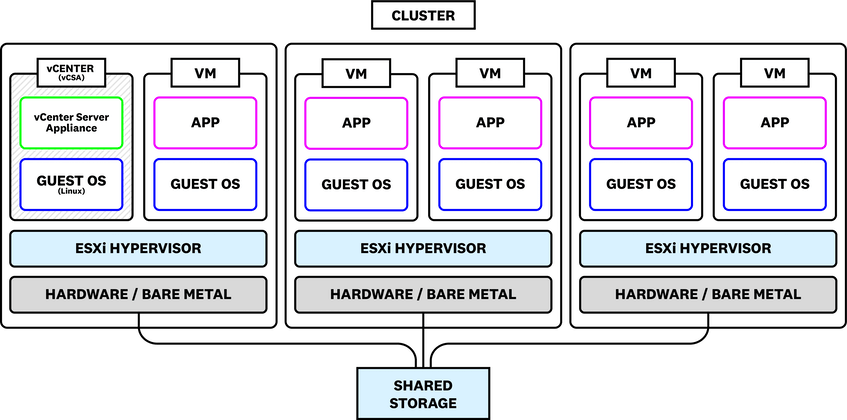
متریک های مهم برای مانیتورینگ vmware
اکنون که با چند کامپوننت اصلی vSphere و معماری کلی آن آشنا شدیم، حال اجازه دهید نگاهی به متریک های مهمی بیندازیم که میخواهید برای مانیتورینگ محیط vSphere خود در VM، هاست و Cluster نیاز دارید و باید بدانها توجه کنید.در حالی که vSphere صدها متریک را ارائه کرده، در اینجا ما چند مورد کلیدی را شناسایی کرده ایم که باید روی آنها تمرکز کنیم. همانطور که در بالا گفته شد، این متریک ها را می توان به پنج دسته متریک های Summary، Cpu، Memory، disk و network تقسیم بندی کرد.
ما همچنین به رخدادهای vSphere نگاه خواهیم کرد که اطلاع در مورد فعالیت کلاستر و سلامت و وضعیت کامپوننتهای محیط مجازی شما ارائه می دهند.
هنگام مانیتورینگ vsphere، از ماشین های مجازی گرفته تا هاست های ESXi که آنها را اجرا می کنند تا Cluster هایی که زیرساخت شما را تشکیل می دهند، مهم است که وضعیت و performance هر لایه از محیط خود را دنبال کنید. مهم است بدانیم که کدام بخش از زیرساخت ما تامین کننده منابع و کدام بخش مصرف کننده این منابع است. به عنوان مثال، VM ها منابع را از منابع فیزیکی مانند هاست ها و Cluster های ESXi گرفته و Consume یا مصرف می کنند. Resource pool ها هم میتوانند منابع را تهیه و هم مصرف کنند، زیرا میتوان همزمان نقش parent و child را به آنها اختصاص داد (یعنی child یک Resource Pool میتواند parent دیگری باشد). همانطور که vSphere را مانیتور می کنید، می خواهید مطمئن شوید که منابع به راحتی در دسترس بوده، به طور موثر استفاده می شوند و توسط بخش های خاصی از زیرساخت شما با قربانی کردن سایر بخش های محیط مصرف نمی شود.
متریک های Summary
متریک های Summary از vSphere به شما یک نمای سطح بالا از اندازه و سلامت زیرساخت شما ارائه می دهد، مواردی مانند تعداد cluster ها در محیط شما و تعداد هاست ها و VM ها که در حال حاضر در حال اجرا هستند را گزارش می دهد. مشخص کردن اندازه محیط vSphere می تواند به شما در تصمیم گیری های allocation یاا تخصیص کمک کند، چرا که می دانید چه تعداد هاست و VM درخواست منابع خواهند کرد.
تعداد هاست و ماشین مجازی ESXi
مانیتورینگ تعداد کل هاستهای ESXi و VM ها میتواند دید خوبی از سطح بالا و وضعیت محیط vSphere شما ارائه دهد. اگر تغییرات قابل توجهی در هر کدام وجود داشته باشد، یا اگر تعداد گزارش شده هاست یا ماشین مجازی به طور قابل توجهی با تعداد مورد انتظار شما متفاوت است، ارزش بررسی دارد. به عنوان مثال، اگر افت غیرمنتظره ای در VM ها وجود داشته باشد، می تواند نشانه ای از پیکربندی نادرست یا اختلاف منابع در هاست باشد. در مورد ماشین های مجازی، می توانید گزارش های vSphere خود را برای عیب یابی بررسی کنید.
متریک های CPU
در vSphere، دو لایه از متریک های CPU وجود دارد که باید در نظر گرفته شوند: CPU فیزیکی (pCPU) و CPU مجازی (vCPU). همانطور که از نام آنها پیداست، pCPU به تعداد پردازنده های موجود در هاست های فیزیکی اشاره دارد در حالی که vCPU به تعداد پردازنده های منطقی موجود در یک هاست اشاره دارد که به یک ماشین مجازی اختصاص داده می شوند.هنگامی که vm ای vCPU را به عنوان ظرفیت پردازش فیزیکی خود می بیند، هر workload روی آن VM روی pCPU آن هاست اجرا می شود. بهطور پیشفرض، هاست ها، workload های vm ها را در تمام pCPUهای موجود برنامهریزی میکنند، به این معنی که تمام ماشینهای مجازی روی یک هاست، processor time را به اشتراک میگذارند. اگر تعداد vCPU های تخصیص داده شده در کل VM ها برابر یا کمتر از pCPU های موجود باشد، بحثی وجود ندارد. اما، برای استفاده کارآمدتر از منابع، طبیعی است که تعداد vCPU های اختصاص داده شده در تمام ماشین های مجازی از تعداد pCPU های موجود بیشتر باشد (یعنی بیش از مقدار واقعی) زیرا بعید است که همه VM ها به 100 درصد از vCPU های خود در یک زمان نیاز داشته باشند. اما، هرچه این نسبت بیشتر شود، ماشین های مجازی بیشتر باید منتظر بمانند تا قبل از اینکه بتوانند به CPU فیزیکی دسترسی پیدا کنند(درصد cpu ready افزایش پیدا می کند). هر چه ماشینهای مجازی زمان بیشتری را در انتظار دسترسی به CPU بگذرانند، اجرای task ها کندتر خواهد بود و performance کلی VM کاهش مییابد.
برای مانیتور موثر محیط vSphere، جمعآوری متریک های CPU از هر دو لایه فیزیکی و مجازی مهم است که این شامل دانستن اینکه چه مقدار CPU از نظر فیزیکی بر روی هاست و در بین Cluster ها در دسترس است و میزان استفاده VM ها چقدر است، که این امر به شما کمک میکند تعیین کنید که آیا محیط مجازی شما به خوبی کار میکند و اینکه آیا باید آن را افزایش یا کاهش دهید یا تخصیص CPU را تنظیم کنید. مثلا VM های خاص با پیکربندی share ها یا تعیین رزرو و limit مورد نیاز باشد.

cpu.readiness.avg
میانگین درصد زمانی که یک VM در وضعیت ready صرف می کند و منتظر دسترسی به pCPU است.cpu.wait
مقدار کل زمان (میلیثانیه) که یک vm در وضعیت انتظار صرف میکند (یعنی ماشین مجازی به CPU دسترسی دارد اما منتظر کارهای اضافی VMKernel می ماند).cpu.usage.avg
ظرفیت pCPU یک هاست ESXi که توسط VMهایی که روی آن کار می کنند استفاده می شود(بر حسب درصد).cpu.TotalCapacity.avg
ظرفیت کل pcpu یک هاست ESXi که در دسترس VM ها است(بر حسب MHz).CPU readiness
متریک CPU readiness درصد زمانی را که یک VM برای اجرای یک workload آماده است، دنبال می کند، اما باید در هاست ESXi منتظر بماند تا آن را برنامه ریزی(schedule) کند، زیرا CPU فیزیکی کافی در دسترس نیست. مانیتورینگ بر زمان CPU readiness می تواند به شما ایده خوبی در مورد اینکه آیا ماشین های مجازی شما به طور موثر کار می کنند یا زمان زیادی را صرف انتظار و ناتوانی در اجرای workload خود می کند، به شما می دهد.در حالی که مقداری زمان CPU readiness می تواند طبیعی و بدیهی باشد، Vmware توصیه می کند یک Alert تنظیم کنید تا اگر این متریک از 5 درصد فراتر رفت، به شما اطلاع دهد. ماشین های مجازی که درصد قابل توجهی از زمان خود را در حالت ready سپری می کنند، قادر به اجرای task های خود نخواهند بود، که این امر می تواند منجر به Performance ضعیف اپلیکیشن ها و احتمالاً ارورهای timeout و downtime شود.
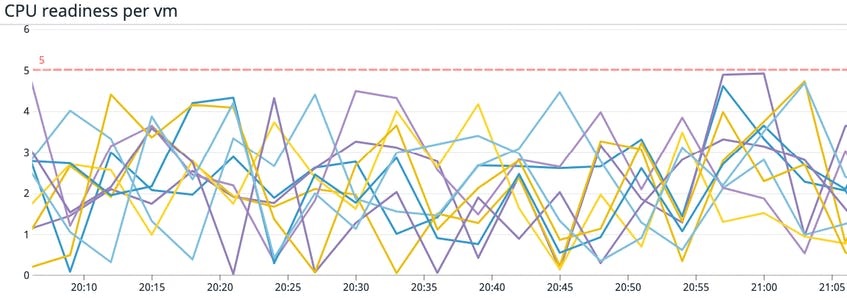
دلیل اصلی زمانهای readiness طولانی، VMهای زیاد در همان هاست esxi است که درصدد دسترسی به منابع CPU هستند.
CPU wait
در حالیکه CPU readiness درصد زمانی است که یک VM برای available CPU منتظر میماند، متریک CPU wait به شما میگوید چقدر زمان، بر حسب میلیثانیه یک VM که توسط هاست ESXi برنامهریزی شده، idle است یا منتظر است تا فعالیت VMKernel قبل از اجرا کامل شود. فعالیت های VMkernel که می تواند به افزایش زمان CPU wait کمک کند شامل کارهایی مانند I/O و memory swapping می باشد.یک CPU wait بزرگ لزوما به معنای مشکل نیست. از آنجایی که متریک CPU wait ترکیبی از idle time و زمان صرف شده در انتظار VMKernel برای تکمیل task های جداگانه می باشد. مقدار بالا در این متریک ممکن است فقط به این معنی باشد که ماشین مجازی task های خود را تکمیل کرده و بنابراین idle است. برای تعیین اینکه آیا زمان wait بالا نتیجه انتظار در عملیات I/O و memory swapping است، می توانید به تفاوت بین زمان گزارش شده CPU wait و CPU idle نگاه کنید.
اگر مشخص شد که زمان CPU wait بالا نتیجه انتظار در فعالیت VMKernel است، این امر می تواند منجر به کاهش performance ماشین مجازی شود و باید متریک های مموری و دیسک را که در ادامه بدانها هم می پردازیم، بررسی کنید تا علت احتمالی آن را شناسایی کنید.
CPU usage
CPU usage می تواند یک شاخص کلیدی برای performance کلی محیط vSphere باشد و مانیتورینگ آن در سطوح مختلف بسیار مهم است. در سطح هاست، متریک cpu.usage.avg به مدیران امکان می دهد تا بررسی کنند که چه درصدی از CPU فیزیکی موجود یک هاست ESXi توسط vm های در حال اجرا بر روی آن استفاده میشود. اگر VM ها شروع به استفاده از بخش بزرگی از CPU هاست (به عنوان مثال، بالای 90 درصد) کنند، احتمالا با افزایش CPU readiness و مشکلات subsequent latency، مواجه می شوید.
شما باید CPU usage را در سطح vm هم مانیتور کنید. بسته به نوع workload که ماشینهای مجازی شما اجرا میکنند، ممکن است ماشینهای مجازی روی هاست های خاصی از CPU نزدیک به ظرفیت (مثلاً برنامهریزیشده برای workload های سنگین) استفاده کنند، بنابراین مانیتورینگ روی این متریک برای ایجاد یک مبنا مهم است.
مانیتورینگ CPU usage در هاست و VM ها بصورت مجزا می تواند به شناسایی مشکلاتی مانند هاست های کم استفاده یا ماشین های مجازی ضعیف کمک کند. برای مثال، اگر میبینید که ماشینهای مجازی شما دائماً از CPU بالا استفاده میکنند، باید هاستهای ESXi خود را بیشتر کنید، تنظیمات تخصیص CPU ماشینهای مجازی خود را تنظیم کنید، یا اگر ماشینهای مجازی روی یک هاست مستقل در حال اجرا هستند، هاست را به یک Cluster اضافه کنید.
CPU total capacity
Vm هایی که روی یک هاست یا کلاستر کار می کنند که همگی به صورت مشترک به pcpu دسترسی دارند، بنابراین ظرفیت کلی میتواند یک bottleneck مشترک باشد و اغلب مکان خوبی برای بررسی مشکلات performance است. در vSphere، ظرفیت کل، مقدار کل pCPU را که بر حسب مگاهرتز اندازهگیری میشود، توصیف میکند که به منظور برنامهریزی برای VM ها در دسترس است. ظرفیت کل pcpu به ظرفیت فیزیکی هاست های ESXi شما (یعنی تعداد پردازنده ها و هسته ها) و مشخصات آنها (مثلاً پشتیبانی از Hyperthreading) بستگی دارد.شما میتوانید این متریک را در هر هاست یا برای دید وسیعتر از منابع CPU موجود، در سطح هر کلاستر مشاهده کنید. اگر به شما از CPU readiness بالا اطلاع داده شده، شاید به این معنی باشد که ظرفیت کل موجود در هاست شما کم است و در نتیجه VM ها مجبور شده اند مدت بیشتری برای دسترسی به CPU منتظر بمانند.
متریک های Memory
مانند CPU، مموری اغلب می تواند یک محدودیت منابع جدی در محیطهای مجازی باشد که در آن بسیاری از ماشینهای مجازی باید ظرفیت محدودی را share کنند.در vSphere، سه لایه memory وجود دارد که باید از آنها آگاه بود:
host physical memory یا حافظه موجود برای هایپروایزرهای ESXi که روی سرور فیزیکی نصب است.
guest physical memory که حافظه موجود برای سیستم عامل های در حال اجرا بر روی ماشین های مجازی است.
guest virtual memory که حافظه موجود در سطح اپلیکیشن یک ماشین مجازی است.
هر VM مقدار پیکربندی شده ای از RAM فیزیکی هاست خود را دارد که سیستم عامل مهمان می تواند بدان دسترسی داشته باشد. با این حال، این اندازه پیکربندی شده با مقدار حافظه ای که هاست واقعاً به آن اختصاص می دهد متفاوت است، که به نیاز ماشین مجازی و همچنین به share ها، limit ها یا رزروهای پیکربندی شده بستگی دارد. به عنوان مثال، اگر یک VM به مقدار 2 گیگ رم برای آن پیکربندی شده باشد، هاست ESXi ممکن است تنها نیاز باشد که 1 گیگابایت را بر اساس workload واقعی(یعنی برنامهها یا فرآیندهای در حال اجرا) به آن اختصاص دهد. توجه داشته باشید که اگر هیچ محدودیتی در حافظه VM تنظیم نشده باشد، اندازه پیکربندی شده آن به عنوان limit آن عمل می کند.
هنگامی که یک ماشین مجازی روشن می شود، ESXI هاست اصلی آن مجموعه ای از memory address را ایجاد می کند که با memory address های ارائه شده به سیستم عامل مهمان در حال اجرا در vm مطابقت دارند. هنگامی که اپلیکیشنی که روی یک vm اجرا میشود در تلاش است که از یک memory page عمل read و write را انجام دهد، سیستم عامل مهمان vm بین guest virtual memory و guest physical memory مانند یک سیستم غیر مجازی(non-virtualized system) ترجمه میشود. در عوض، هایپروایزر ESXi هاست درخواستهای مموری را رهگیری کرده و آنها را به حافظه هاست فیزیکی map می کند.
ESXi همچنین یک map (به نام shadow page tables) از هر memory translation را حفظ می کند: guest virtual به guest physical و guest physical به host physical، که این امر ثبات را در تمام لایه های حافظه تضمین می کند.
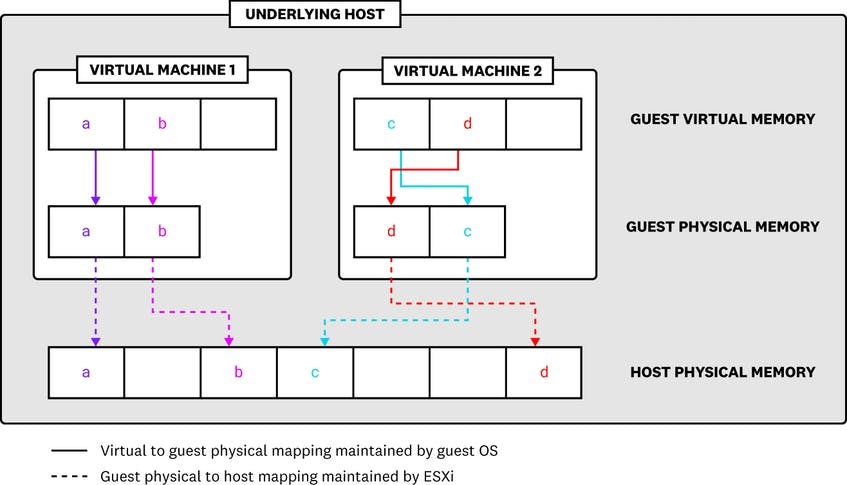
این رویکرد به memory virtualization به این معنی است که هر ماشین مجازی فقط میزان استفاده از RAM خود را می بیند در حالی که هاست ESXi می تواند مموری را در تمام VM های در حال اجرا، تخصیص و مدیریت کند. همچنین یک VM نمی داند که هاست ESXi چه زمانی باید مموری را به ماشین های مجازی دیگر اختصاص دهد. اگر guest physical memory در تمام VM های در حال اجرا (به اضافه هر گونه استفاده از overhead ضروری) برابر با حافظه فیزیکی هاست باشد، مشکلی نیست. ولی بعضا مموری overcommitted می شود(یعنی مجموع حافظه فیزیکی مهمان بیشتر از حافظه فیزیکی هاست است)، هاست های ESXI برای بازیابی حافظه آزاد از ماشینهای مجازی و تخصیص آن به سایرین، به تکنیکهای memory reclamation متوسل میشوند. استراتژیهای Resource overcommitment و memory reclamation به بهینهسازی استفاده از حافظه کمک میکنند، اما مانیتورینگ متریک های که ballooning و swapping را انجام میکنند بسیار مهم است، زیرا استفاده بیش از حد از هر کدام میتواند منجر به کاهش performance ماشین مجازی شود.
تکنیک های memory reclamation
بررسی VMware Transparent Page Sharing یا TPS در VMware
بررسی تکنیک VMware Memory Ballooning
بررسی Memory Compression در vmware
بررسی Hypervisor Swapping در Vmware
مکان swap file ماشین مجازی در vmware

mem.vmmemctl: مقدار حافظه (KiB) که درایور memory balloon که هاست در صورت کمبود حافظه آن را بازیابی می کند(این کامپوننت با نصب vmware tools روی vm نصب می شود).
mem.swapin: مقدار حافظه (KiB) که هاست ESXi از دیسک به VM در واقع Swap می کند (physical storage).
mem.swapout: مقدار حافظه (KiB) یک هاست ESXi از یک VM به دیسک (ذخیره سازی فیزیکی) swap می کند.
mem.active: مقدار حافظه اختصاص داده شده که VMkernel یک هاست تخمین می زند که یک VM به طور فعال از آن استفاده می کند(KiB).
mem.consumed: مقدار مموری از مموری فیزیکی هاست (KiB) که در واقع به یک ماشین مجازی اختصاص داده شده است.
mem.usage.avg: درصدی از کل حافظه پیکربندی شده یک VM که به طور فعال توسط VM استفاده می شود.
درصد حافظه هاست که در واقع به ماشین های مجازی اختصاص داده شده است.
mem.TotalCapacity.avg: مقدار حافظه میزبان فیزیکی (MiB) رزرو شده و در دسترس برای ماشین های مجازی
Balloon driver (vmmemctl) capacity
در روی هر vm در vSphere می توان یک درایور balloon با نام vmmemctl را نصب کرد. اگر یک هاست ESXi حافظه فیزیکی کمی را برای تخصیص داشته باشد (یعنی کمتر از 6 درصد حافظه آزاد)، می تواند مموری را از guest physical memory ماشین های مجازی بازیابی کند. با این حال، از آنجایی که هایپروایزرهای ESXi از اینکه چه memory page هایی دیگر توسط ماشین های مجازی استفاده نمی شود، اطلاعی ندارند، درخواست هایی را به درایورهای balloon ارسال می کنند تا با جمع آوری مموری استفاده نشده از ماشین مجازی، اصطلاحا inflate یا باد شوند(مثل بالون). هاست ESXi میتواند آن مموری را از درایور balloon که inflate شده بگیرد و سپس آن را به ماشینهای مجازی دیگر تخصیص دهد. این تکنیک به memory ballooning معروف است.در حالی که ballooning میتواند به هاست های ESXi در مواقعی که مموری آنها کم است کمک کند، اگر زیاد انجام شود میتواند Performance ماشین مجازیی را کاهش دهد. اگر سیستم عامل مهمان بعداً نتواند به حافظهای که توسط درایور ballooning از آن گرفته شده و توسط هاست بازیابی شده، دسترسی پیدا کند و اگر ballooning برای برآوردن نیازهای رم کافی نباشد، هاست های ESXi ممکن است شروع به استفاده از swap memory برای برآورده کردن نیازهای مموری VM ها کنند، که منجر به کاهش شدید Performance اپلیکیشن ها می شود. بنابراین باید یک alter برای هر مقدار مثبت برای mem.vmmemctl تنظیم کنید، که نشان می دهد هاست ESXi از حافظه available فراتر رفته است.
Memory swapped in/out
هنگامی که یک میزبان ESXi یک ماشین مجازی را provision می کند، فایل های disk storage فیزیکی را به نام فایل های swap اختصاص می دهد. اندازه فایل Swap بر اساس اندازه پیکربندی شده ماشین مجازی، کمتر از مموری رزرو شده تعیین می شود. به عنوان مثال، اگر یک VM با 3 گیگابایت مموری پیکربندی شده باشد و دارای 1 گیگابایت رزرو باشد، یک فایلswap با ظرفیت 2 گیگابایت خواهد داشت. بهطور پیشفرض، فایلهای swap ماشین مجازی با virtual disk آن در shared storage قرار میگیرند.اگر حافظه فیزیکی هاست کم شود، و memory ballooning، حافظه کافی را برای پاسخگویی سریع به تقاضاها بازیابی نمی کند (یا اگر درایور ballooning غیرفعال شده باشد یا vmware tools روی vm نصب نشده باشد)، هاست های ESXi شروع به استفاده از فضای swap برای write و read داده ها خواهند کرد.
read و write داده ها روی دیسک بسیار بیشتر از استفاده از مموری طول می کشد و می تواند سرعت ماشین مجازی را به شدت کاهش دهد، بنابراین Memory swap باید به عنوان آخرین راه حل در نظر گرفته شود. اطمینان حاصل کنید که با تنظیم alert هایی از هر گونه افزایشی مطلع می شوید. اگر متوجه افزایش swap شدید، بد نیست که وضعیت درایورهای VM balloon را نیز بررسی کنید زیرا swap ممکن است نشان دهد که balloon نتوانسته حافظه کافی را بازیابی کند. بهتر است که روی Vm ها حتما vmware tools نصب باشد و حتما vmware tools را در Vm ها آپدیت کنید.
Active memory versus consumed memory
برای اینکه یک VMKernel به دقت تشخیص دهد که چه مقدار حافظه به طور فعال توسط ماشین های مجازی استفاده می شود، باید هر memory page ای را که از آن خوانده شده یا روی آن نوشته شده است مانیتور کند. اما اینکار overhead زیادی دارد. در عوض، VMKernel از algorithmic learning برای تولید تخمینی از active memory usage هر VM استفاده می کند. VMKernel این تخمین به عنوان متریک mem.active گزارش می دهد که بر حسب KB اندازه گیری می شود.Active memory معیار اندازه گیری real-time خوبی برای میزان استفاده از رم vm های شما است و مانیتور بر آن در کنار consumed memory میتواند به شما کمک کند تا تشخیص دهید که آیا به vm ها مموری کافی اختصاص داده شده یا خیر. اگر Active memory یک ماشین مجازی به طور قابل توجهی کمتر از consumed memory آن باشد، به این معنی است که حافظه بیشتری نسبت به نیاز خود به آن اختصاص داده شده است و در نتیجه، هاست memory available کمتری نسبت برای سایر Vm ها در دسترس دارد. برای اصلاح این موضوع، مقدار رم یا حافظه رزرو VM را تغییر دهید.
Memory usage
Memory usage در سطح VM، متریک mem.usage مشخص می کند که یک vm چند درصد از حافظه پیکربندی شده خود را به طور فعال استفاده می کند. در حالت ایده آل، یک VM نباید همیشه از تمام حافظه پیکربندی شده خود استفاده کند. اگر به طور مداوم از بخش بزرگی از حافظه پیکربندی شده خود استفاده می کند، VM در برابر هرگونه افزایش memory usage مقاومت کمتری خواهد داشت. در این شرایط ، پیکربندی دوباره مموری ماشین مجازی، آپدیت تنظیمات memory allocationآن (shares, reservations و limit) یا انتقال vm به کلاستری با مموری بیشتر را در دستور کارتان داشته باشید.در سطح میزبان، memory usage نشان دهنده درصدی از حافظه فیزیکی میزهاست بان ESXi است که در حال مصرف است. اگر memory usage در سطح هاست به طور مداوم بالاست، احتمالا نمی تواند مموری را برای vm هایی که به آن نیاز دارند فراهم کند و نیاز به اجرای memory ballooning بیشتر می شود و یا حتی استفاده از تکنیک swap memory را آغاز می کند که اصلا جالب نیست و افت performance شدید را تجربه خواهید کرد.
Disk metrics
VM ها از فایلهای بزرگ (یا گروههایی از فایلها) به نام دیسکهای مجازی (به نام فایلهای VMDK یا Virtual Machine Disk file) برای ذخیره فایلهای سیستم عامل خود و اپلیکیشن ها استفاده میکنند. VM ها بهطور پیشفرض با یک دیسک مجازی ایجاد می شوند، اما میتوانید آنها را طوری پیکربندی کنید که تعداد بیشتری داشته باشند. Virtual disk ها در datastore ها قرار دارند که بسته به پیکربندی میتوانند در مکانهای ذخیرهسازی مشترک مختلفی قرار گیرند. گزینه های ذخیره سازی برای ذخیره سازی داده ها شامل local storage و network storage است. شبکه های منطقه ذخیره سازی (SAN) و دستگاه های ذخیره سازی شماره واحد منطقی (LUN) است.Vsphere، I/O دیسک ها و متریک های ظرفیت را در سطوح مختلف از جمله datastore ها، VM ها و هاست های ESXi گزارش میدهد. از آنجایی که چندین هاست و ماشین مجازی از یک دیتا استور share شده استفاده کنند، مانیتورینگ در سطح datastore میتواند دیدی سطح بالا و تجمیعی از Performance دیسک را به شما ارائه دهد. با این حال، برای پیگیری سلامت یک ماشین مجازی یا هاست خاص، مطمئن شوید که Performance دیسکهای مجازی (یعنی آنچه سیستم عامل مهمان در اختیار دارند) و دیسکهای فیزیکی (یعنی آنچه که در اختیار هاست های شماست) را مانیتور کنید. پیگیری و دنبال کردن متریک های دیسک در هر یک از این سطوح میتواند به ارائه تصویر کاملتر از سلامت کلاستر و troubleshoot در مواردی که مشکلات رخ میدهد کمک کند.
VM ها از storage controller ها برای دسترسی به virtual disk ها در یک دیتا استور استفاده می کنند. Storage controller به ماشینهای مجازی اجازه میدهند دستوراتی را به هاست ESXi که روی آن در حال اجرا هستند، ارسال کنند که پس از آن دستورات را به دیسک مجازی مناسب هدایت میکند. از آنجایی که VM ها دستورات را از طریق هاست های ESXi به datastore ها ارسال میکنند، متریک های مانیتورینگ که آگاهی در مورد throughput و latency ارائه میدهند میتواند به شما کمک کند تا اطمینان حاصل کنید که هاستها و ماشینهای مجازی قادر به دسترسی موثر و بدون وقفه به فضای ذخیرهسازی فیزیکی هستند.
disk.commandsAborted
تعداد کل دستورات i/o که توسط هاست esxi لغو و abort شده را نشان می دهد.disk.busReset
تعداد دستورات disk bus reset توسط ماشین مجازی را نشان می دهد.diskspace.provisioned.latest
مقدار فضای ذخیره سازی available در دیتا استور بر حسب KB است.virtualDisk.actualUsage
مقدار فضای ذخیره سازی داده (KB) که در واقع توسط ماشین های مجازی روشن روی هاست استفاده می شود.disk.totalLatency.avg
میانگین زمان (میلیثانیه) که یک هاست ESXi به طول می انجامد تا دستور ارسال شده توسط یک ماشین مجازی را پردازش کند.component.readLatency.avg
میانگین زمان (میلیثانیه) که Component مشخصشده برای پردازش دستور read طول میکشد.component.writeLatency.avg
میانگین زمان (میلیثانیه) که Component مشخصشده برای دستور write طول میکشد.component.read.avg
میانگین مقدار داده (KB/s) خوانده شده توسط Component مشخص شده است.component.write.avg
میانگین مقدار داده (KB/s) نوشته شده روی یک component مشخص است.disk.queueLatency.avg
میانگین زمانی (ms) که هر دستور I/O قبل از اجرا در صف VMkernel صرف میکند.disk.usage.avg
میانگین i/o بر حسب KB/s یک کامپوننت مشخص، می باشد.Disk commands aborted
در vSphere، یک storage device cluster واحد ممکن است datastore هایی را در خود جای دهد که به بسیاری از ماشینهای مجازی سرویس می دهد. اگر دستورات ماشینهای مجازی به سختافزار ذخیرهسازی که در آن datastore قرار دارند افزایش یابد، شاید آن storage با مشکل overload و unresponsive مواجه شود. اگر این اتفاق رخ دهد، هاست ESXi ای که دستورات را ارسال کرده، آنها را لغو(abort) می کند. از آنجایی که دستورات abort شده می تواند منجر به کاهش Performance ماشینهای مجازی و حتی crash آنها شوند، شاید بخواهید که متریک disk.commandsAborted روی 0 بماند. اگر یک هاست ESXi شروع به لغو دستورات کند، و علت آن ترافیک بالای فرمان VM به دیتا استور است، باید افزایش storage داشته باشید تا فایل های vm ها بین آنها توزیع شود و بدین ترتیب از ارسال فرمان VM فقط به یک Storage جلوگیری شود.Disk bus resets
اگر یک دستگاه ذخیرهسازی با دستورات read و write بیش از حد از یک هاست ESXi غرق شود، یا اگر با مشکل سختافزاری مواجه شود و در abort کردن دستورات دچار fail شود، تمام دستورات منتظر در صف خود را پاک میکند. به این حالت disk bus reset گفته می شود. disk bus reset نشانه ای از bottleneck در دیسک استوریج ها است و میتواند منجر به کاهش Performance ماشین مجازی شود زیرا VM ها باید دوباره آن درخواستها را ارسال کنند. Disk bus reset معمولاً در محیطهای vSphere سالم اتفاق نمیافتد، بنابراین باید هر ماشین مجازی با مقدار متریک disk.bus.reset را بررسی کنید. برای حل این مشکل، ادمین ها ممکن است نیاز به استفاده از Storage vMotion برای redistribute ماشینهای مجازی و دیسکهای مجازی در دیتااستورهای مختلف داشته باشند تا Performance را بهینه کنند.Datastore provisioned capacity and actual VM usage
Storage یک منبع محدود است. متریک diskspace.provisioned.latest میزان فضای ذخیرهسازی موجود در دیتا استورهایی را که هاست ESXi با آنها ارتباط برقرار میکند دنبال کرده، در حالی که virtualDisk.actualUsage به شما امکان میدهد تا میزان فضای دیسک را vm های روشن روی آن هاست به طور فعال استفاده میکنند، بررسی کنید. مرتبط کردن این متریک ها می تواند به شما کمک کند که اگر فضای دیسک مناسبی را برای آنچه VM ها نیاز دارند، در نظر بگیرید.Datastore های پر یا نزدیک به ظرفیت کامل، می تواند باعث ایجاد out of space error و کاهش performance ماشین مجازی شوند. شما باید ظرفیت را افزایش دهید و یا اینکه vm را به Datastore دیگری انتقال دهید. یا ماشینهای مجازی غیرفعال را حذف کنید که فضا بیشتر آزاد شود.
Disk latency
مانیتورینگ latency کلیدی است برای اطمینان از اینکه VM های شما به طور مؤثر و بدون تأخیر با دیسک های مجازی خود ارتباط برقرار می کنند. Total disk latency مدت زمانی را که یک هاست ESXi برای پردازش درخواست ارسال شده از یک VM به یک دیتا استور به طول می انجامد، بر حسب میلی ثانیه اندازه گیری می کند. ماینتورینگ total disk latency می تواند به شما کند که ببینید آیا esxi مطابق انتظار شما عمل می کند یا خیر. افزایش Latency یا تأخیر بالا، نشانههای خوبی هستند که نشان میدهند مشکلی در محیط شما وجود دارد، اما میتوانند دلایل مختلفی از جمله bottleneck در منابع یا مشکلات در سطح اپلیکیشن داشته باشند.اگر متوجه مشکلی در total latency شدید، میتوانید میانگین تأخیر عملیات خواندن (disk.readLatency.avg) و نوشتن (disk.writeLatency.avg) را نیز بررسی کنید تا تعیین کنید که کدام یک در latency کلی تأثیر بیشتری دارد. به طور مشابه، میتوانید تأخیرهای read و write را در سطح VM، host و datastore بررسی کنید تا تعیین کنید که چه inventory object ای در افزایش total latency نقش دارد.
ارتباط disk latency بالا با سایر متریک های استفاده از منابع می تواند در تعیین اینکه آیا علت اصلی کمبود available memory یا CPU است یا خیر، مفید باشد. در این صورت، میتوانید تشخیص دهید که کدام ماشینهای مجازی روی هاست یا کلاستر بیشترین مصرف منابع را دارند و یا منابع بیشتری را به آن ماشینها اختصاص دهید یا آنها را به دیتااستورهای با ظرفیت بیشتر منتقل کنید.
Queue latency
بسته به پیکربندی، دستگاههای ذخیرهسازی مانند LUN تعداد محدودی دستور دارند که میتوانند در هر زمان در صف قرار دهند. هنگامی که حجم دستورات ماشین مجازی ارسال شده از یک میزبان ESXi بیشتر از مقداری باشد که یک دستگاه ذخیره سازی می تواند در صف قرار دهد، آن دستورات در VMKernel شروع به قرار گرفتن در صف می کنند. متریک disk.queueLatency میانگین زمانی را که دستور از VM صرف می شود تا در صف VMkernel قرار بگیرد را دنبال و مشخص می کند. هر چه یک فرمان بیشتر در یک صف منتظر بماند تا توسط دیسک پردازش شود، vm ای که آن دستور را ارسال کرده Performance بدتری خواهد داشت. queue latency بالا ارتباط نزدیکی با total latency بالا دارد چرا که دستورات معمولاً باید در یک صف منتظر بمانند.برای درک بهتر performance محیط تان، queue latency را در کنار disk.usage.avg مانیتور کنید. برای مثال، میتوانید تعیین کنید که آیا افزایش queue latency با کاهش کلی throughput مطابقت دارد یا خیر.
مانند total latency، queue latency را میتوان با انتقال ماشینهای مجازی به دیتا استور با ظرفیت دیسک بیشتر، افزایش queue depth دیتااستور یا storage I/O control حل کرد. بافعال بودن storage I/O control یا sioc میتوانید به VMها share منابع ذخیرهسازی و یک آستانه تأخیر(latency threshold) دستوری بدهید که پس از عبور از آن، به vSphere میگوید تا شروع به تخصیص فضای ذخیرهسازی به VMها بر اساس share هایشان کند. این می تواند به کاهش فشار I/O و کاهش queue latency کمک کند.
Disk throughput
برای اطمینان از اینکه datastore ها، هاست های ESXi و ماشین های مجازی شما دستورات read و write را بدون وقفه پردازش می کنند، I/O throughput آن ها را برای مشاهده فعالیت آنها زیر نظر بگیرید. مانیتورینگ throughput در سطوح مختلف و ارتباط آن با سایر متریک ها می تواند به شما در شناسایی bottleneck ها و تعیین دقیق محل وقوع یک مشکل کمک کند.متریک های network
محیط vSphere از شبکهای از سرورهای فیزیکی که در واقع ESXI Host هستند، و یک یا چند شبکه منطقی از VM ها که روی همان هاست ها اجرا میشوند، تشکیل شده است. جمع اوری متریک های ارور و usage از شبکه های فیزیکی و مجازی در کل محیط برای اطمینان از اتصال سالم بسیار مهم است. مشکلات Network connectivity می تواند شما را از اجرای وظایف مهم مثل VM provisioning، migration که به ارتباطات شبکه ای نیاز دارند، باز دارد.مانیتورینگ network throughput شبکه هاست و ماشینهای مجازی به شما کمک میکند متوجه شوید که آیا شبکهتان مطابق انتظار عمل میکند یا اینکه نیاز به پیکربندی مجدد تنظیمات شبکه (به عنوان مثال، افزودن آداپتور شبکه دیگر به VM) است یا خیر.
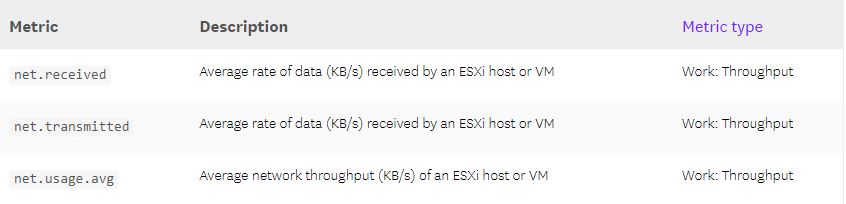
net.received
: میانگین data rate دریافت شده توسط یک هاست ESXi یا VM بر حسب KB/s است.net.transmitted
: میانگین data rate ارسال شده از یک هاست ESXi یا VM بر حسب KB/s است.net.usage.avg
: میانگین network throughput یک هاست Esxi یا vm بر حسب KB/s است.Network received and network transmitted
این متریک ها بر حسب کیلوبایت در ثانیه، سرعت شبکه را از هاست یا VM است، مشخص و دنبال می کند. این متریک ، همراه با متریک total network usage یا کل استفاده از شبکه (net.usage.avg) می توانند درک پایه ای از ترافیک شبکه بین هاست های ESXi یا VM ها ارائه دهند. اگر baseline ای را برای رفتار شبکه تعیین کرده اید، پس می توانید یک alert تنظیم کنید تا شما را از انحرافات (به عنوان مثال، افزایش یا افت) آگاه کند که احتمال دارد به مشکلاتی در سخت افزار اصلی شما (به عنوان مثال، خراب شدن کانکشن سرور به هر دلیلی) یا پیکربندی نادرست و اشتباه در VM های ویندوزی و یا لینوکسی اشاره کند.Tasks and events
به طور پیش فرض vSphere، task ها و event هایی را که در VM ها، هاست های ESXi و vCenter در محیط مجازی شما رخ می دهد، ثبت و رکورد می کند. این موارد می تواند شامل لاگین کاربران، خاموش کردن VM، certification expiration ها، قطعی و اتصال هاست ها باشد. Tasks and events مربوط به vsphere به شما یک دید از سلامت و فعالیت محیط مجازی تان میدهد و مواردی مانند خرابیها و خطاها را گزارش میکند تا در صورت ناسالم بودن محیط به شما اطلاع دهد. از آنجایی که task ها را می توان schedule کرد بررسی وضعیت آنها به شما می گوید که در چرخه اجرای خودشان، در کجا قرار دارند. مانیتورینگ task ها و event ها، میتواند به شما کمک کند که بدانید چگونه تغییرات در محیط شما، مانند روشن شدن VM، میتواند بر استفاده از منابع تأثیر بگذارد و منجر به کمبودهایی شود.هر هاست، tasks and events را در log file ها . در مکان های مختلف ثبت می کند. برخی از این فایل های مهم شامل موارد زیر است:
/var/log/vmkernel.log
لاگ های VMKernel که شامل دادههای مربوط به device discovery، storage and network events و VM startup ها، می باشد./var/log/syslog.log
لاگ های System message که شامل دادههای مربوط به task های schedule شده و تعاملات با هاست های ESXi است./var/log/auth.log
لاگ های Authentication که شامل دادههای مربوط به User login ها و User logout ها هستند./vmfs/volumes/datastore/virtual machine/vwmare.log
لاگ های vm که شامل دادههایی درباره ماشینهای مجازی خاص، مانند migration ها و تغییرات virtual hardware است.مانیتورینگ event ها در این لاگ فایل ها میتواند به شما کمک کند از فعالیتهای کلی در کلاسترها آگاه باشید و همچنین ممیزی انجام دهید و مشکلاتی را که در محیط تان رخ میدهد بررسی کنید.



نمایش دیدگاه ها (0 دیدگاه)
دیدگاه خود را ثبت کنید: