خوش آموز درخت تو گر بار دانش بگیرد، به زیر آوری چرخ نیلوفری را
متریک های مهم برای مانیتورینگ performance در vmware

فناوری مجازی سازی به لطف انعطاف پذیری، سرعت، قابلیت اطمینان و سهولت مدیریتی که ارائه می دهد، به طور گسترده ای مورد استفاده قرار می گیرد. در ماشین های فیزیکی، خرابی یا performance ضعیف یک ماشین بر اپلیکیشن های در حال اجرا روی همان ماشین تاثیر می گذارد. با مجازیسازی، چندین ماشین مجازی (VM) روی یک هاست فیزیکی اجرا میشوند و کاهش سرعت هاست بر اپ های در حال اجرا روی تمام ماشینهای مجازی تأثیر میگذارد. از این رو، مانیتورینگ performance در یک زیرساخت مجازی حتی مهمتر از یک زیرساخت فیزیکی است.

performance اپلیکیشن های در حال اجرا روی VM ها به عوامل زیادی بستگی دارد:
تمامی منابع سخت افزاری موجود روی هاست در اختیار هایپروایزور esxi قرار می گیرد و توسط Esxi در اختیار vm ها قرار می گیرد. اگر فقط تعداد کمی از ماشین های مجازی مقدار زیادی از منابع (CPU، حافظه، دیسک) را مصرف کنند، ماشین های مجازی دیگر ممکن است در صورت نیاز، به منابع دسترسی نداشته باشند. این به نوبه خود بر performance اپلیکیشن ها در سایر ماشین های مجازی تأثیر می گذارد.
ادمین ها می توانند منابع موجود برای VM ها را محدود کنند. البته اگر محدودیت اصولی اعمال نشده باشد، performance اپلیکیشن های روی vm ها را تحت تاثیر قرار خواهد داد.
Administrator ها اغلب منابع هاست ها را over-commit می کنند زیرا همه ماشین های مجازی که روی این هاست ها اجرا می شوند ممکن است همزمان به منابع نیاز نداشته باشند. در حالی که over-commitment استفاده بهتر از منابع سختافزاری را تضمین میکند، Administrator باید سطوح استفاده واقعی روی هاستها برای شناسایی و تصحیح موقعیتهایی که یک هاست فیزیکی کمبود منابع دارد و در نتیجه performance ماشینهای مجازی روشن بر روی آن تحتتاثیر قرار میگیرد را مانیتور کنند.
تخصیص بیش از حد منابع به VM راه حل خوبی نیست. اولا، تخصیص بیش از حد منجر به استفاده ناکافی از سخت افزار می شود و در نتیجه بازده ضعیفی را به همراه دارد. ثانیاً، تخصیص بیش از حد CPU به یک ماشین مجازی میتواند باعث waiting برای در دسترس بودن منابع CPU کافی شود و در performance بر عملکرد تأثیر جدی دارد.
بنابراین، چگونه می توان تعیین کرد که مقدار مناسب منابع برای تخصیص به یک VM چقدر است؟ پاسخ به این سوال در دنبال کردن و پیگری میزان استفاده از منابع تسوط ماشینهای مجازی در طول زمان، تعیین میزان استفاده در حال نرمال و سپس اندازهگیری صحیح ماشینهای مجازی بر این اساس نهفته است.
اما چگونه می توان متریک های استفاده از منابع را برای VM ها پیگیریی کرد و کدام یک مهم هستند؟ VMware vSphere شامل بسیاری از کامپوننت های منابع مختلف است. دانستن اینکه این کامپوننت ها چه هستند و چگونه هر کامپوننت بر تصمیمات resource management تأثیر می گذارد، کلید مدیریت کارآمد performance ماشین مجازی است. در این پست، 9 متریک و مهم را که هر مدیر VMware باید به طور مداوم دنبال و پیگیری کند را مورد بحث قرار خواهیم داد.
تکنیک های memory reclamation
بررسی VMware Transparent Page Sharing یا TPS در VMware
بررسی تکنیک VMware Memory Ballooning
بررسی Memory Compression در vmware
بررسی Hypervisor Swapping در Vmware
مکان swap file ماشین مجازی در vmware
به طور معمول، هایپروایزر بخشی از حافظه هاست فیزیکی را به هر ماشین مجازی اختصاص می دهد. سیستم عامل مهمان که در داخل یک VM اجرا می شود، از کل حافظه موجود برای هاست فیزیکی بی اطلاع است. Memory ballooning سیستم عامل مهمان را از کمبود حافظه هاست آگاه می کند. هر زمان که هاست فیزیکی با مشکل کمبود مموری مواجه شود درایور balloon نصب شده در سیستم عامل مهمان تعیین می کند که آیا مموری استفاده نشده را می توان از هر vm بازیابی کرد یا خیر. سپس درایور balloon شروع به inflate یا باد شدن می کند که حافظه را از سیستم عامل مهمان بگیرد و این رم گرفته شده را به هایپروایزر می دهد. هایپروایزر هم این رم احیا شده را در اختیار vm دیگری که نیازمند مموری بوده قرار می دهد تا بتواند کار کند.
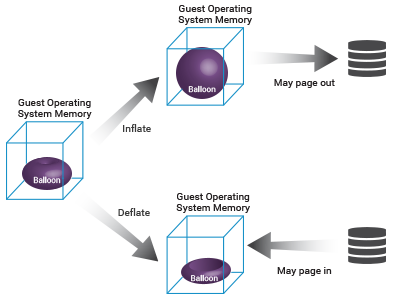
بالون کردن استفاده کارآمد از حافظه فیزیکی را به قیمت performance ماشین مجازی امکان پذیر می کند. به این دلیل که بالون کردن بیش از حد مموری روی هایپروایزر می تواند باعث شود سیستم عامل مهمان از روی دیسک بخواند(بخشی از رم که reclaim شده روی هارد قرار می گیرد). I/O دیسک های بالا می تواند Performance ماشین مجازی را بسیار کاهش دهد. برای جلوگیری از memory ballooning، مدیران باید به طور مداوم میزان حافظه ای که هایپروایزر از ماشین های مجازی بازیابی می کند را دنبال کنند.
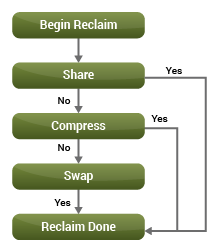
Swapping در سیستم عامل مهمان و سطح هایپروایزر انجام می شود.
در سطح hypervisor-level swapping: memory page ها در ماشین های مجازی به یک فضای swap هایپروایزر منتقل می شود. هر VM به فضای swap مخصوص به خود متصل است. هنگامی که سیستم عامل مهمان از فضای swap به یک memory page دسترسی پیدا می کند، vSphere با swapping در آن page از فضای swap، دسترسی را مدیریت می کند. vCPU waits می تواند در طول عملیات swap-in افزایش پیدا کند و تاثیر بسیار بد روی performance ماشین مجازی بگذارد. علاوه بر این، فضای swap ناکافی نیز می تواند performance ماشین مجازی را کاهش دهد.
در سطح guest OS-level swapping: هر بار که CPU به یک virtual memory page در سیستم عامل مهمان دسترسی پیدا می کند، آن memory page به مموری فیزیکی swap می شود. به این ترتیب، virtual memory page هاکه به طور مکرر به آنها دسترسی پیدا می کنند، در حافظه فیزیکی در دسترس قرار می گیرند تا بتوانند به سرعت مورد استفاده قرار بگیرند. Memory page هایی که به ندرت مورد استفاده قرار می گیرند در استوریج swap می شوند. بنابراین، با swapping، به دلیل read و write مکرر، و نرخ بالای swapping بین حافظه فیزیکی و storage، خطر disk I/O بالا و کندی پردازش وجود دارد.
از نقطه نظر performance monitoring ضروری است که مدیران بدانند چه زمانی و برای چه مدت یک VM در حالت vCPU wait و ready بوده است.
یک snapshot کل وضعیت ماشین مجازی را در زمان تهیه snapshot می تواند ذخیره و Capture کند که این شامل محتویات حافظه ماشین مجازی، تنظیمات ماشین مجازی و وضعیت تمام دیسک های مجازی متعلق به vm است.
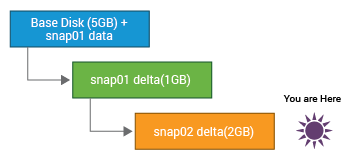
پس از گرفتن یک snapshot، هر تغییری که باید در دیسک مجازی اصلی (VMDK) انجام شود، در یک فایل اسنپ شات در حال رشد نوشته می شود. بسته به سطح فعالیت روی ماشین مجازی، با گذشت زمان، این فایل snapshot میتواند حتی به اندازه فایل دیسک مجازی اصلی افزایش یابد. در جایی که چندین فایل اسنپ شات وجود دارد، استفاده از فضای دیسک ترکیبی آنها حتی می تواند از اندازه فایل دیسک مجازی اصلی فراتر رود. Snapshot های بزرگ می تواند منجر به کاهش فضای ذخیره سازی شود و حتی روی Performance ماشین مجازی هم تاثیر داشته باشد. شما باید مراقب فایل های Snapshot ماشین های مجازی باشد. رشد فایل های Snapshot می تواند روی عملکرد تاثیر بد داشته باشد.
VMware همچنین توصیه می کند که از یک Snapshot بیش از 72 ساعت استفاده نشود. علاوه بر افزایش بی مورد فضای ذخیره سازی، فایل های اسنپ شات قدیمی نیز می توانند مشکلاتی را در کنترل نسخه برای برنامه ها و ماشین های مجازی ایجاد کنند.
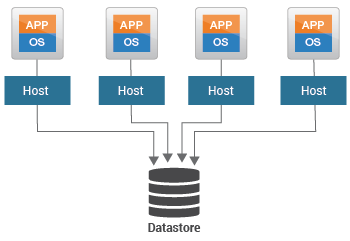
استفاده بیش از حد از فضای دیسک در datastore ها نیز می تواند منجر به کاهش قابل توجهی در عملکرد VM شود. اگر بیش از 75 درصد از فضای دیسک یک دیتا استور استفاده شود، نشان دهنده یک «جنگ برای فضا» بالقوه در میان ماشینهای مجازی در آن datastore است. در چنین شرایطی، مدیران باید سریعا ماشین مجازی را که تشنه فضا است شناسایی کنند و بفهمند که چرا فضا را انقدر حریصانه مصرف می کنند. در غیر این صورت، این امر میتواند باعث شود سایر ماشینهای مجازی که از همان دیتا استور استفاده میکنند، با مشکلات جدی performance مواجه شوند.
مسائل مربوط به در datastore availability و استفاده از فضا در جایی که datastore روی استوریج های خارجی مانند SAN/NAS پیکربندی شده است، آشکارتر میشوند. دلیل آن این است که در این مورد، پیکربندی نادرست یا مشکل در عملیات داخلی یا از دست دادن ارتباط با دستگاه ذخیرهسازی خارجی نیز میتواند بر سلامت datastore تأثیر بگذارد. بنابراین، مدیران باید بتوانند storage را همراه با ماشینهای مجازی و دیتا استورها مانیتور کنند، مسائل را بهطور هوشمند در سطوح مجازیسازی و ذخیرهسازی مرتبط کرده و بهدقت نقطهی bottleneck را تشخیص و متمایز کنند.
مانند سختافزار هاست، وضعیت سخت افزار VM نیز باید دنبال شود، زیرا خرابیهای سختافزاری که توسط یک VM تجربه میشود میتواند روی availability و performance ماشین مجازی تأثیر منفی بگذارد.
متریک های CPU برای مانیتورینگ در vmware
منظور CPU Ready در vmware چیست؟
بررسی متریک های مموری در VMware vSphere
نکاتی برای بهینه سازی Performance سخت افزار مجازی در VMware

performance اپلیکیشن های در حال اجرا روی VM ها به عوامل زیادی بستگی دارد:
تمامی منابع سخت افزاری موجود روی هاست در اختیار هایپروایزور esxi قرار می گیرد و توسط Esxi در اختیار vm ها قرار می گیرد. اگر فقط تعداد کمی از ماشین های مجازی مقدار زیادی از منابع (CPU، حافظه، دیسک) را مصرف کنند، ماشین های مجازی دیگر ممکن است در صورت نیاز، به منابع دسترسی نداشته باشند. این به نوبه خود بر performance اپلیکیشن ها در سایر ماشین های مجازی تأثیر می گذارد.
ادمین ها می توانند منابع موجود برای VM ها را محدود کنند. البته اگر محدودیت اصولی اعمال نشده باشد، performance اپلیکیشن های روی vm ها را تحت تاثیر قرار خواهد داد.
Administrator ها اغلب منابع هاست ها را over-commit می کنند زیرا همه ماشین های مجازی که روی این هاست ها اجرا می شوند ممکن است همزمان به منابع نیاز نداشته باشند. در حالی که over-commitment استفاده بهتر از منابع سختافزاری را تضمین میکند، Administrator باید سطوح استفاده واقعی روی هاستها برای شناسایی و تصحیح موقعیتهایی که یک هاست فیزیکی کمبود منابع دارد و در نتیجه performance ماشینهای مجازی روشن بر روی آن تحتتاثیر قرار میگیرد را مانیتور کنند.
تخصیص بیش از حد منابع به VM راه حل خوبی نیست. اولا، تخصیص بیش از حد منجر به استفاده ناکافی از سخت افزار می شود و در نتیجه بازده ضعیفی را به همراه دارد. ثانیاً، تخصیص بیش از حد CPU به یک ماشین مجازی میتواند باعث waiting برای در دسترس بودن منابع CPU کافی شود و در performance بر عملکرد تأثیر جدی دارد.
بنابراین، چگونه می توان تعیین کرد که مقدار مناسب منابع برای تخصیص به یک VM چقدر است؟ پاسخ به این سوال در دنبال کردن و پیگری میزان استفاده از منابع تسوط ماشینهای مجازی در طول زمان، تعیین میزان استفاده در حال نرمال و سپس اندازهگیری صحیح ماشینهای مجازی بر این اساس نهفته است.
اما چگونه می توان متریک های استفاده از منابع را برای VM ها پیگیریی کرد و کدام یک مهم هستند؟ VMware vSphere شامل بسیاری از کامپوننت های منابع مختلف است. دانستن اینکه این کامپوننت ها چه هستند و چگونه هر کامپوننت بر تصمیمات resource management تأثیر می گذارد، کلید مدیریت کارآمد performance ماشین مجازی است. در این پست، 9 متریک و مهم را که هر مدیر VMware باید به طور مداوم دنبال و پیگیری کند را مورد بحث قرار خواهیم داد.
تکنیک های memory reclamation
بررسی VMware Transparent Page Sharing یا TPS در VMware
بررسی تکنیک VMware Memory Ballooning
بررسی Memory Compression در vmware
بررسی Hypervisor Swapping در Vmware
مکان swap file ماشین مجازی در vmware
Memory Ballooning
Memory ballooning یکی از تکنینک های memory reclamation یا بازپس گیری و احیای مموری است که توسط esxi انجام می شود تا به سیستم هاست فیزیکی اجازه دهد تا مموری استفاده نشده را از ماشین های مجازی بازیابی کند، به این معنی که vm ها که با کمبود مموری مواجه هستند می توانند از حافظه بازیابی شده استفاده کنند.به طور معمول، هایپروایزر بخشی از حافظه هاست فیزیکی را به هر ماشین مجازی اختصاص می دهد. سیستم عامل مهمان که در داخل یک VM اجرا می شود، از کل حافظه موجود برای هاست فیزیکی بی اطلاع است. Memory ballooning سیستم عامل مهمان را از کمبود حافظه هاست آگاه می کند. هر زمان که هاست فیزیکی با مشکل کمبود مموری مواجه شود درایور balloon نصب شده در سیستم عامل مهمان تعیین می کند که آیا مموری استفاده نشده را می توان از هر vm بازیابی کرد یا خیر. سپس درایور balloon شروع به inflate یا باد شدن می کند که حافظه را از سیستم عامل مهمان بگیرد و این رم گرفته شده را به هایپروایزر می دهد. هایپروایزر هم این رم احیا شده را در اختیار vm دیگری که نیازمند مموری بوده قرار می دهد تا بتواند کار کند.
بالون کردن استفاده کارآمد از حافظه فیزیکی را به قیمت performance ماشین مجازی امکان پذیر می کند. به این دلیل که بالون کردن بیش از حد مموری روی هایپروایزر می تواند باعث شود سیستم عامل مهمان از روی دیسک بخواند(بخشی از رم که reclaim شده روی هارد قرار می گیرد). I/O دیسک های بالا می تواند Performance ماشین مجازی را بسیار کاهش دهد. برای جلوگیری از memory ballooning، مدیران باید به طور مداوم میزان حافظه ای که هایپروایزر از ماشین های مجازی بازیابی می کند را دنبال کنند.
Memory Swapping
Memory swapping زمانی رخ می دهد که رم هاست به شدت کم شده باشد. وقتی ballooning، compression و TPS پاسخگوی تامین رم مورد نیاز هاست نباشد، Memory Swapping راه حل دیگری است که برای تامین رم استفاده می شود.
Swapping در سیستم عامل مهمان و سطح هایپروایزر انجام می شود.
در سطح hypervisor-level swapping: memory page ها در ماشین های مجازی به یک فضای swap هایپروایزر منتقل می شود. هر VM به فضای swap مخصوص به خود متصل است. هنگامی که سیستم عامل مهمان از فضای swap به یک memory page دسترسی پیدا می کند، vSphere با swapping در آن page از فضای swap، دسترسی را مدیریت می کند. vCPU waits می تواند در طول عملیات swap-in افزایش پیدا کند و تاثیر بسیار بد روی performance ماشین مجازی بگذارد. علاوه بر این، فضای swap ناکافی نیز می تواند performance ماشین مجازی را کاهش دهد.
در سطح guest OS-level swapping: هر بار که CPU به یک virtual memory page در سیستم عامل مهمان دسترسی پیدا می کند، آن memory page به مموری فیزیکی swap می شود. به این ترتیب، virtual memory page هاکه به طور مکرر به آنها دسترسی پیدا می کنند، در حافظه فیزیکی در دسترس قرار می گیرند تا بتوانند به سرعت مورد استفاده قرار بگیرند. Memory page هایی که به ندرت مورد استفاده قرار می گیرند در استوریج swap می شوند. بنابراین، با swapping، به دلیل read و write مکرر، و نرخ بالای swapping بین حافظه فیزیکی و storage، خطر disk I/O بالا و کندی پردازش وجود دارد.
VM CPU Wait and VM CPU Ready
vCPU یک ماشین مجازی می تواند در یکی از چهار حالت اصلی run، wait، co-stop و ready باشد.از نقطه نظر performance monitoring ضروری است که مدیران بدانند چه زمانی و برای چه مدت یک VM در حالت vCPU wait و ready بوده است.
vCPU Wait Time
یک ماشین مجازی که منتظر انجام یک کار است ممکن است در لحظه به vCPU خود نیاز نداشته باشد. زمانی که VM برای این منظور vCPU خود را در انتظار نگه داشت، زمان vCPU wait است. به طور معمول، یک VM تا زمانی که چیزی رخ ندهد و کاری برای انجام نباشد می تواند منتظر بماند. به این حالت انتظار، حالت idle می گویند. بالا و پایین در زمان انتظار idle ناچیز است زیرا به معنی مشکل نیست. از طرف دیگر، اگر VM منتظر تکمیل read/write در storage باشد و تا زمانی که کامل نشود نمی تواند کاری انجام دهد، بدان I/O wait گفته می شود. برخلاف idle wait، I/O wait بر performance تاثیر خواهند داشت. I/O wait بیشتر، کندی VM را در پی خواهد داشت. I/O wait همچنین نیز نشاندهنده unavailable بودن، overload شدن storage هم می تواند باشد. پس مهم است که ادمین ها متریک vCPU I/O wait را مانیتور کنند.vCPU Ready Time
vCPU ready time درصد زمانی است که یک VM آماده کار است اما نمی تواند یک CPU فیزیکی برای اجرا در اختیار داشته باشد. یکی از دلایل رایج برای بالا بودن vCPU Ready Time اشتراک بیش از حد است. اگر به یک VM به میزان بیشتری از CPUهای فیزیکی (pCPU) موجود در هاست اختصاص داده شود، در زمان هایی که لود کار زیاد است و یا زمانی که همه چیز عادی است، همه vCPU ها باید تمام وقت کار کنند، بسیاری از vCPU ها ممکن است به دلیل کمبود pCPU کار نکنند. پس نتیجه اینکه VM و اپلیکیشن های در حال اجرا بر روی آن از قدرت پردازشی کمتری برخوردار خواهند بود که به نوبه خود باعث کاهش Performance ماشین مجازی خواهد شد. پس مانیتورینگ vCPU ready time برای هر vm بسیار مهم است. اگر این متریک برای VM بیش از 5٪ باشد، نشان دهنده کندی VM است. شما میتوانید این متریک را CPU usage هاست مرتبط کنید تا متوجه شوید که آیا در همان زمانی که vCPU ready time افزایش مییابد، کمبودی برای منابع فیزیکی CPU وجود دارد یا خیر. اگر چنین است، پس vm بیش از حد روی هاست قرار گرفته است. برای تأیید، همچنین می توانید تعداد pCPU های موجود در هاست و تعداد vCPU های اختصاص داده شده به هر VM را بررسی کنید. بعضا به vm هایی vcpu های زیادی تخصیص داده شده که با تغییر و کمتر کردن آن هم Performance ماشین مجازی را بهتر می کنید و هم اینکه ready را کاهش می دهید. ready بر حسب درصد بوده و همیشه باید زیر 5 درصد باشد.Large and Old VM Snapshots
یک snapshot کل وضعیت ماشین مجازی را در زمان تهیه snapshot می تواند ذخیره و Capture کند که این شامل محتویات حافظه ماشین مجازی، تنظیمات ماشین مجازی و وضعیت تمام دیسک های مجازی متعلق به vm است.
پس از گرفتن یک snapshot، هر تغییری که باید در دیسک مجازی اصلی (VMDK) انجام شود، در یک فایل اسنپ شات در حال رشد نوشته می شود. بسته به سطح فعالیت روی ماشین مجازی، با گذشت زمان، این فایل snapshot میتواند حتی به اندازه فایل دیسک مجازی اصلی افزایش یابد. در جایی که چندین فایل اسنپ شات وجود دارد، استفاده از فضای دیسک ترکیبی آنها حتی می تواند از اندازه فایل دیسک مجازی اصلی فراتر رود. Snapshot های بزرگ می تواند منجر به کاهش فضای ذخیره سازی شود و حتی روی Performance ماشین مجازی هم تاثیر داشته باشد. شما باید مراقب فایل های Snapshot ماشین های مجازی باشد. رشد فایل های Snapshot می تواند روی عملکرد تاثیر بد داشته باشد.
VMware همچنین توصیه می کند که از یک Snapshot بیش از 72 ساعت استفاده نشود. علاوه بر افزایش بی مورد فضای ذخیره سازی، فایل های اسنپ شات قدیمی نیز می توانند مشکلاتی را در کنترل نسخه برای برنامه ها و ماشین های مجازی ایجاد کنند.
Idle/Orphaned VMs
ماشینهای مجازی Idle آن دسته از ماشینهای مجازی هستند که همچنان در حال اجرا هستند و به مصرف با ارزش CPU، حافظه و منابع ذخیرهسازی ادامه میدهند، حتی اگر دیگر استفاده نمیشوند. به عنوان مثال، فرض کنید یک VM به کارمندی اختصاص داده شده است که بعداً استعفا می دهد. اما اگر آن VM نه از کار افتاده باشد و نه متعاقباً به کاربر دیگری اختصاص داده شود، آن VM به یک VM غیرفعال تبدیل می شود.VM Disk Read/Write IOPS and Throughput
رایج ترین و در عین حال دقیق ترین شاخص های سلامت دیسک مجازی، disk IOPS و throughput است. سطح throughput که یک دیسک مجازی می تواند ارائه دهد و تعداد عملیات read/write ای که می تواند در یک ثانیه پشتیبانی کند، تعیین می کند که دیسک مجازی با چه سرعتی می تواند دستورات یا درخواست های I/O را پردازش کند. اگر اندازه یک دیسک مجازی با throughput یا I/O کافی نباشد، ماشین مجازی که از آن دیسک مجازی استفاده میکند و اپلیکیشن هایی که روی آن ماشین مجازی کار میکنند کندی قابل توجهی را تجربه خواهند کرد. بعلاوه، اگر یک VM/application بیش از مقداری که دیسک مجازی برای پشتیبانی پیکربندی شده است، throughput ارسال کند، فشار روی vCPU و حافظه مجازی آن VM افزایش مییابد. این به نوبه خود می تواند باعث شود ماشین مجازی CPU فیزیکی و مموری بیشتری به دست آورند و در نتیجه باعث شود ماشین های مجازی دیگر با منابع فیزیکی محدودتری کار کنند. پس احتمالا شاهد افت Performance این vm ها خواهیم بود. برای جلوگیری از چنین مشکلاتی، مدیران باید به دقت بر throughput و IOPS روی هر دیسک مجازی مانیتورینگ داشته باشند، این مقادیر را با CPU usage و memory usage مرتبط کنند و به طور فعال تعیین کنند که آیا اندازه فضای ذخیرهسازی باید تغییر کند یا خیر.Datastore Capacity Usage and Availability
VMware vSphere از دیتا استورها برای ذخیره تمامی فایل های مرتبط با ماشین های مجازی خود استفاده می کند. دیتا استور یک واحد ذخیره سازی منطقی است که می تواند از فضای دیسک در یک دستگاه فیزیکی، یک پارتیشن دیسک یا چندین دستگاه فیزیکی استفاده کند.
استفاده بیش از حد از فضای دیسک در datastore ها نیز می تواند منجر به کاهش قابل توجهی در عملکرد VM شود. اگر بیش از 75 درصد از فضای دیسک یک دیتا استور استفاده شود، نشان دهنده یک «جنگ برای فضا» بالقوه در میان ماشینهای مجازی در آن datastore است. در چنین شرایطی، مدیران باید سریعا ماشین مجازی را که تشنه فضا است شناسایی کنند و بفهمند که چرا فضا را انقدر حریصانه مصرف می کنند. در غیر این صورت، این امر میتواند باعث شود سایر ماشینهای مجازی که از همان دیتا استور استفاده میکنند، با مشکلات جدی performance مواجه شوند.
مسائل مربوط به در datastore availability و استفاده از فضا در جایی که datastore روی استوریج های خارجی مانند SAN/NAS پیکربندی شده است، آشکارتر میشوند. دلیل آن این است که در این مورد، پیکربندی نادرست یا مشکل در عملیات داخلی یا از دست دادن ارتباط با دستگاه ذخیرهسازی خارجی نیز میتواند بر سلامت datastore تأثیر بگذارد. بنابراین، مدیران باید بتوانند storage را همراه با ماشینهای مجازی و دیتا استورها مانیتور کنند، مسائل را بهطور هوشمند در سطوح مجازیسازی و ذخیرهسازی مرتبط کرده و بهدقت نقطهی bottleneck را تشخیص و متمایز کنند.
VM Network Connectivity
هنگامی که کاربر شکایت می کند که یک VM غیرقابل دسترسی یا کند است، دلیل آن ممکن است همیشه این نباشد که VM خاموش شده یا مشکل در منابع رم و cpu است. اغلب چنین مسائل و مشکلاتی را می توان در شبکه جستجو کرد. بنابراین، مانیتورینگ سلامت VM به تنهایی کافی نخواهد بود. همچنین مهم است که مدیران اتصال به هر vm را از منظر خارجی مانیتور کنند. دنبال کردن وضعیت و performance سوئیچ های مجازی و virtual port ها نیز به troubleshoot موثر مشکلات اتصال کمک می کند.Hardware Health
خرابی سخت افزار سلامت هاست vSphere و ماشین های مجازی را می تواند با مخاطره جدی مواجه کند. پردازندههایی که از کار افتادهاند، فنهایی که کار نمیکنند، جهشهای ناگهانی و قابل توجه دما/ولتاژ سختافزار و غیره، میتوانند سریعا و خیلی شدید به یک هاست فیزیکی آسیب برسانند و هم هایپروایزور و هم VM های روی آن را خراب کنند.مانند سختافزار هاست، وضعیت سخت افزار VM نیز باید دنبال شود، زیرا خرابیهای سختافزاری که توسط یک VM تجربه میشود میتواند روی availability و performance ماشین مجازی تأثیر منفی بگذارد.
متریک های CPU برای مانیتورینگ در vmware
منظور CPU Ready در vmware چیست؟
بررسی متریک های مموری در VMware vSphere
نکاتی برای بهینه سازی Performance سخت افزار مجازی در VMware


دسته بندی مطالب خوش آموز

نمایش دیدگاه ها (0 دیدگاه)
دیدگاه خود را ثبت کنید: