خوش آموز درخت تو گر بار دانش بگیرد، به زیر آوری چرخ نیلوفری را
متریک های بسیار مهم vmware مربوط به Performance مانیتورینگ


20 متریک بسیار مهم Performance ای Vmware که اهمیت بسیار دارند!

مجازی سازی چالش های جدیدی را برای مدیریت دیتاسنتر معرفی می کند. امروزه اپلیکیشن ها برای منابع زیرساختی داینامیک و Share شده مانند Storage، CPU cycle ها و memory رقابت میکنند و همین مشکل تخصیص منابع را پیچیده می کند که با اضافه شدن ماشین های مجازی بیشتر، اوضاع بدتر هم می شود و همین bottleneck برای Performance ROI ضعیف و مشتریان ناراضی می شود.
در این مطلب ما 20 متریک مهم در Vmware Vcenter را جمع آوری و آنها را مورد بررسی قرار خواهیم می دهیم که نشان میدهد چه bottleneck های مرتبط با منابع و مشکلات ظرفیت رخ میدهد. برای هر متریک، ما در مورد اینکه چه چیزی باعث مشکلات Performance می شود، چگونه این متریک ها به شناسایی مشکلات کمک می کنند، چه نوع تجزیه و تحلیل بیشتری باید انجام شود تا تأیید شود که یک مشکل خاص باعث مشکلات ماشین مجازی (VM) می شود، و نحوه رفع مشکلات بحث می کنیم. سپس ما ابزاری را توصیه می کنیم که داده های این 20 متریک را تجزیه و تحلیل می کند تا بتوانید به سرعت مشکلات Performance ماشین مجازی خود را پیدا کرده و حل کنید. Capacity bottleneck ها می تواند در دیسک، disk I/O، network، memory یا منابع CPU مربوط به VM usage رخ دهد. وقتی یک VM یا هاست در مضیقه بوده و در bottleneck گرفتار شده، اپلیکیشن های موجود در VM ها به کندی واکنش نشان میدهند و همین امر منجربه عدم تکمیل اجرای دستورات و حتی هنگی برنامه ها و تاخیر و Latency می شود.
آنالیز و تجزیه و تحلیل متریک های ارائه شده در این مقاله به شما کمک می کند تا علت مشکلات Performance ای VM و یافتن راه حل های دقیق را پیدا کنید. لازم به ذکر است که تجزیه و تحلیل کامل برای آشکار کردن مشکلات می تواند بسیار سخت باشد. نظارت و مانیتورینگ کافی بر این متریک ها شامل جمعآوری دادهها از هر VM حداقل 10 بار در ساعت و تجزیه و تحلیل دادهها برای هر VM، host، cluster و resource pool است.
مقدار داده به دست آمده بسیار زیاد است در یک محیط ساده 100-VM، نزدیک به 17 میلیون بخش داده در یک دوره 30 روزه جمع آوری می شود. پس می خواهیم این معیارها یا متریک های کلیدی را مورد بررسی قرار دهیم. با ما همراه باشید.
منظور CPU Ready در vmware چیست؟
متریک های مهم برای مانیتورینگ محیط vmware vsphere
متریک های مهم برای مانیتورینگ performance در vmware
متریک های CPU
ابتدای امر به بررسی متریک هایی که مربوط به CPU هستند می پردازیم. بعضا در مورد متریک های مربوط به CPU در محیط مجازی سوئ تفاهم هایی عارض می شود حالا ما سعی می کنیم به نحو درستی این متریک ها را بررسی کنیم.cpu.extra.summation
یک مقدار در این متریک نشان دهنده این است که bottleneck ای در محیط مجازی وجود دارد.متریک cpu.ready.summation در سطح VM به صورت realtime اندازهگیری میشود و ارزیابی میکند که آیا VM دارای مشکلات CPU Ready است یا خیر. مشکلات CPU Ready ناشی از استفاده بیش از حد از CPU است. CPU Ready بالا زمانی رخ می دهد که ماشینهای مجازی برای استفاده از هستههای فیزیکی محدود با یکدیگر رقابت میکنند و wait time ادامه مییابد. wait time هم به این دلیل است که یک ماشین مجازی منتظر می ماند تا CPU transaction ماشین مجازی دیگر به پایان برسد قبل از اینکه نوبت transaction خودش فرا برسد. تأخیر زمانی ناشی از CPU Ready باعث کندی در پردازش VM می شود که به عنوان یک مشکل performance ای از آن یاد می شود.
بر اساس best practice های VMware، یک bottleneck مربوط به CPU Ready زمانی رخ می دهد که بیش از تایمی بیش از 5 درصد در CPU transaction توسط VM در زمان Wait برای آماده شدن CPU فیزیکی باشد. پس CPU Ready همیشه باید زیر 5 درصد باشد. بیش از 5 درصد یعنی بین VM ها برای دسترسی به CPU فیزیکی جنگ است. اگرچه VMware تلاش میکند تا یک ماشین مجازی را برای استفاده از یک هسته فیزیکی بهگونهای schedule کند که بارها Balance شوند، اما اگر تعداد زیادی Virtual Core برای هر هسته فیزیکی وجود داشته باشد، این schedule کردن میتواند مشکل ساز شود. به منظور جلوگیری از گسترش بیش از حد منابع CPU، بسیاری از سازمان ها درصدد این هستند که نسبت به سه VCPU یک CPU فیزیکی را به عنوان maximum resource allocation در دستور کار داشته باشند.
CPU Ready می تواند مشکلی دشوار برای شناسایی باشد و علت بسیاری از مشکلات performance است. راه حل برای مشکلات مربوط به CPU این است که لودهای VM را rebalance کنید تا استفاده فیزیکی CPU را گسترش دهید یا تخصیص منابع CPU به VM ها را به درستی انجام دهید تا این زمان کاهش پیدا کند. نکته مهم این است که می توان با مانیتورینگ CPU utilization با cpu.usagemhz از مشکلات مربوط به CPU Ready جلوگیری کرد.
cpu.usagemhz.average
متریک cpu.usagemhz.average استفاده فیزیکی CPU را اندازه گیری می کند و در سطح VM اندازه گیری می شود. مقدار بالا در متریک cpu.usagemhz.average نشان دهنده این است که استفاده از CPU برای یک CPU فیزیکی در حال نزدیک شدن به استفاده کامل بوده و یا به استفاده کامل رسیده است. این امکان وجود دارد که VM های با اندازه بالا در این متریک ها، Lag هایی را در Performance تجربه کنند، زیرا استفاده بیش از حد از CPU میتواند منجر به مشکلات CPU Ready شود زیرا فرامین منتظر میمانند تا cycle های پردازش در دسترس قرار گیرند.اگرچه یک متریک cpu.usagemhz.average بالا به تنهایی خود لزوماً به معنای وقوع bottleneck نیست، اما می تواند یک نشانگر هشدار دهنده باشد که باید به دقت دنبال شود. این متریک می تواند به ادمین کمک کند تا به طور فعال از مشکلات Performance جلوگیری کند. همچنین، این متریک می تواند در جداسازی علت مشکلات bottleneck در CPU مفید باشد.
برخی از VM ها بعضا از 100 در 100 منابع تخصیص یافته بر اساس نیازهای پردازشی معمولی خود استفاده می کنند، که می تواند منجر به مشکلاتی با سایر VM هایی شود که نیاز به اشتراک گذاری آن منابع دارند. ماشین های مجازی با مقادیر cpu.usagemhz.average بالا باید بر اساس یک بازه زمانی یا طول زمان بررسی شوند تا نحوه CPU Usage در طول زمان فعال بودن VM بررسی شود. تنها راه برای رفع bottleneck های مربوط به CPU، تخصیص منابع بیشتر CPU به VM هایی است که مشکلات ناشی از استفاده بیش از حد از CPU یا CPU overutilization را تجربه می کنند.
متریک بعدی مربوط به Memory می باشد.
متریک های Memory
mem.active.average
متریک mem.active.average در سطح VM جمعآوری میشود و مقدار memory page ای را که به طور فعال توسط یک ماشین مجازی در یک زمان معین استفاده میشود، اندازهگیری میکند. یک VM معمولاً به طور فعال از تمام رم تخصیص داده شده خود در یک زمان معین استفاده نمی کند. بیشتر allocation دادههای دیگری را در خود جای میدهد که اخیراً به آنها دسترسی پیدا کردهاند اما به طور فعال روی آنها کار نمیشود.از آنجایی که یک VM حافظه تخصیص داده شده بیشتری نسبت به استفاده واقعی در یک زمان معین دارد، متریک mem.active.average نشان دهنده مقدار مموری مصرفی یا consume شده یک ماشین مجازی نیست. متریک Mem.consumed.Average اندازه گیری بسیار دقیق تری از کل مموری VM است. با این حال، mem.active.average همچنان باید ارزیابی شود تا ایده بهتری در مورد مقدار حافظه ای که در هر زمان مشخص توسط یک ماشین مجازی به طور فعال مورد استفاده قرار می گیرد، بدست آورید.
ارزیابی این متریک به همراه mem.consumed.average به ارزیابی اینکه آیا به VM مقدار کافی حافظه تخصیص داده شده است یا خیر کمک خواهد کرد. اگر مشکلات مربوط به متریک mem.active.average یافت شد، تنها راه حل آنها افزودن یا تخصیص مموری بیشتر به VM یا انتقال یک VM به هاست با مموری بیشتر است.
mem.consumed.average
متریک mem.consumed.average در سطح VM جمعآوری میشود و مقدار حافظهای را که در کل توسط یک ماشین مجازی مصرف میشود اندازهگیری میکند. یک VM از memory ای که در حال حاضر به طور فعال به عنوان memory page توسط VM استفاده می شود، بیشتر استفاده می کند. بخشی از consumed memoryحافظه ای را در خود جای می دهد که اخیراً استفاده شده است اما به طور فعال به آن دسترسی پیدا نمی شود. حافظه فعال و این «held memory» که با هم جمع شوند برابر با کل حافظه یک ماشین مجازی است، که همان چیزی است که mem.consumed.average اندازهگیری میکند.ارزیابی mem.consumed.average برای تعیین اینکه آیا کمبود مموری بر Performance یک VM تأثیر میگذارد مفید است، زیرا این مقادیر برخی محدودیتهای مموری را نشان میدهند. برای اینکه ببینیم آیا یک VM واقعاً از کمبود مموری در مضیقه است یا نه، مهم است که میانگین mem.active.average را همزمان مورد بررسی قرار کنیم.
بررسی دقیق این متریک و تغییرات در استفاده از منابع بهعنوان عملکرد و کارکرد یک ماشین مجازی در اوج یک دوره زمانی، دیدی و View ای را در مورد میزان مموری اختصاص داده شده توسط یک VM را بدست خواهید آورد. نکته مهم این است که برخی از ماشین های مجازی تمام منابع اختصاص داده شده به خود را consume می کنند و اگر یک ماشین مجازی مقادیر بالای MEM.consumed.average را نشان می دهد، احتمال دارد که باعث و بانی چنین مشکلی در واقع اپلیکیشن، سرویس و کلا برنامه ای باشد که در VM هم اکنون در حال اجرا است. برای آن نوع ماشین های مجازی، استفاده از متریک mem.consumed.average به عنوان آستانه ای برای کمبود حافظه قریب الوقوع کارساز نخواهد بود. تنها راه حل کمبود مموری که توسط mem.consumed.average و mem.active.average نشان داده شده، افزودن یا تخصیص حافظه بیشتر به VM یا انتقال یک VM به هاست با RAM بیشتر است.
mem.overhead.average
متریک mem.overhead.average مقدار حافظه ای را که برای مدیریت حافظه اختصاص داده شده استفاده می شود و در سطح VM به ازای هر میزبان جمع آوری می شود، اندازه گیری می کند.به دلیل روش و شیوه ای که VM ها (و به طور کلی کامپیوترها) از مموری خود استفاده میکنند، باید مقداری RAM برای مدیریت خودشان استفاده شود - یعنی یک کامپیوترها باید کارهایی که منابع خود انجام میدهند را پیگیری کند. این سربار اضافی یا overhead نیاز به استفاده از حافظه بیشتر توسط یک VM نسبت به آنچه صرفاً توسط ادمین تخصیص داده می شود، می باشد. هر چه مقدار RAM ای که برای یک ماشین مجازی تخصیص داده اید بیشتر باشد، حافظه بیشتری نیز در Overhead نیاز است.
VMware جدولی را ارائه می دهد (در شکل زیر) که بر اساس مقدار Memory و تعداد CPU، به طور دقیق مقدار memory overhead مورد نیاز برای هر VM را لیست می کند. از آنجایی که مموری معمولاً سورسی است که بیشترین محدودیت ها را دارد، توجه به متریک mem.overhead.average برای جلوگیری از کمبود مموری غیر آشکار ضروری است.
متریک mem.overhead.average باید هنگام تصمیم گیری در مورد تخصیص مموری برای همه VM ها در یک هاست مانیتور شود. از آنجایی که حافظه اندازه گیری شده توسط متریک mem.overhead.average از کل RAM هاست گرفته می شود، یک هاست در واقع حافظه کمتری نسبت به مجموع کل مموری اختصاص یافته به VM ها در آن هاست خواهد داشت.
برای رفع کمبود مموری که میتواند بر همه VM های موجود روی یک هاست تاثیر می گذارد، به جای اینکه VM ها بیش از مقدار مورد نیازشان رم داشته باشند، باید رم به میزان کافی بدان ها اختصاص دهید. یا حتی می توانید به سرور، RAM بیشتری اضافه کنید و یا VM ها به هاستی که مقدار رم آزاد مناسبی دارد، انتقال دهید.
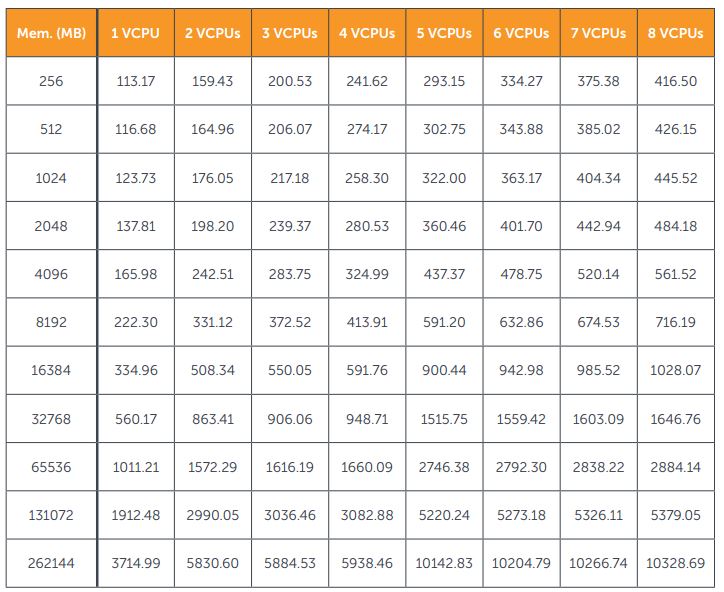
بررسی متریک های مموری در VMware vSphere
بررسی تکنیک VMware Memory Ballooning
بررسی Memory Compression در vmware
بررسی Hypervisor Swapping در Vmware
مکان swap file ماشین مجازی در vmware
Memory swapping: mem.swapin.average, mem.swapout.average and mem.swapped.average
وجود مقادیر در این متریک ها نشان می دهد که یک bottleneck در محیط مجازی وجود دارد. متریک های mem.swapin.average، mem.swapout.average و mem.swapped.average با هم ارزیابی می شوند تا مشخص شود که آیا bottleneck مربوط به memory swapping رخ می دهد یا خیر. این متریک ها در سطح VM اندازهگیری میشوند و با هم میانگین میشوند تا مقداری درصدی را در خروجی نشان دهند.Memory swapping اقدامی است که سرورها برای مدیریت RAM خود انجام می دهند. اگر مموری سرور پر شود و دیگر ظرفیتی برای اطلاعات بیشتر نباشد، سیستم بخشی از محتویات حافظه خود را گرفته و آن را به فضای ذخیره سازی روی یک دیسک "Swap" می کند تا بتواند اطلاعات جدید را در RAM که خالی کرده است، منتقل کند. اگر چیزی از حافظه swap شده مورد نیاز باشد، VM بار مموری که swap شده را از هارد دیسک درخواست می کند و آن را روی رم swap می کند تا روی آن کار شود.
Swapping memory بسیار زمان بر است و می تواند زمان پردازش را بین سه تا پنج مرتبه افزایش دهد، زیرا اطلاعات باید از طریق شبکه به سمت ذخیره سازی حرکت کنند و سپس توسط دیسک پردازش شوند. به همین ترتیب، هنگامی که یک کامپیوتر داده ها را به مموری swap می کند، یک lag time اضافی وجود خواهد داشت که به کل تراکنش پردازش اضافه می کند.
در نتیجه این lag ها یا تاخیر های بزرگ، اگر VM ها مموری Swap کنند، Performance به طور چشمگیری کاهش می یابد. Memory swapping حتی روی Performance دیسک هم تاثیر می کذارد و این هم bottleneck دیگری است که با آن دست و پنجه نرم می کنید و حتما مشتریانتان ناراضی خواهند شد.
VM swapping نشان میدهد که منابع RAM کافی به یک VM تخصیص داده نشده است یا ballooning در حال رخ دادن است که باعث کاهش حجم مموری به VM ها در یک هاست میشود. برای رفع یک bottleneck مربوط به memory swapping باید به یک ماشین مجازی حافظه بیشتری داده شود و آنالیز بیشتر باید انجام شود تا مشخص شود که آیا swap به دلیل ballooning ایجاد شده است یا خیر.
mem.vmmemctl.average(balloon)
یک مقدار در این متریک نشان می دهد که ممکن است یک bottleneck در محیط مجازی رخ دهد وجود مقدار در mem.vmmemctl.average نشان دهنده این است که Ballooning در حال رخ دادن است. Ballooning زمانی اتفاق میافتد که ماشینهای مجازی از منابع حافظه بیشتری استفاده میکنند که شروه به نزدیک شدن به یک محدودیت میکنند. این محدودیت می تواند فیزیکی باشد و یا از طریق محدودیت منابع در Vmware باشد. با این افزایش فعالیت در یک ماشین مجازی تمام منابع share در سایر VM ها بررسی می شوند و اگر حافظه consumed غیرفعال در ماشین های مجازی دیگر وجود داشته باشد، VMware آن منابع را تصاحب کرده و به ماشین مجازی که حافظه آن در حال افزایش است می دهد.بالون کردن بسیار مهم است، زیرا به طور مستقیم به memory swapping متصل است، که یکی از دلایل اصلی مشکلات Performance است. VMware به عنوان راهی برای جلوگیری از کمبود حافظه در Ballooning شرکت می کند، اما روی ماشین های مجازی که رم هم اکنون چندان نیاز آنها نیست، تأثیر می گذارد(یعنی رم را از vm هایی که الان زیاد بدان نیاز ندارند گرفته و به VM هایی که الان رم نیاز دارند، می دهد). Ballooning بسیار مهم است، زیرا به طور مستقیم به memory swapping متصل است، که یکی از دلایل اصلی مشکلات Performance است. مشکلات زمانی رخ می دهند که ماشین مجازی ای که منابع حافظه اش را از دست داده، شروع به افزایش استفاده از آن می کند و شروع به memory swapping روی دیسک می کند تا برای اطلاعاتی که باید روی آن کار کند، فضا ایجاد کند و بدیهی است که این امر منجر به اتفاقات ناخوشی خواهد شد. همانطور که دیدیم، memory swapping می تواند منجر به مشکلات مربوط به throughput و دیسک شود و این bottleneck ها Performance ماشین مجازی را به میزان قابل توجهی کاهش می دهد.
وجود مقدار در متریک mem.vmmemctl.average باید فورا مورد بررسی قرار بگیرد. همچنین با ballooning بررسی کنید که آیا محدودیت های VMware برای VM بدون اطلاع Administrator تنظیم شده است یا خیر. برای حل bottleneck های مربوط به ballooning اندازهگیری صحیح رم برای همه ماشینهای مجازی، افزودن رم بیشتر در صورت لزوم، redeploy کردن ماشینهای مجازی برای rebalance کردن استفاده از منابع مشترک و مهمتر از همه، بررسی اینکه آیا محدودیتهایی در VMware تنظیم شدهاند که برای ماشینهای مجازی مناسب نباشد.
حالا به متریک های مربوط به دیسک در vmware Vsphere می رسیم.
Disk metrics
disk.busResets.summation
نمایش مقدار در این متریک نشان دهنده bottleneck در محیط مجازی است. disk bus reset زمانی است که تمام دستوراتی که در یک HBA یا disk bus در صف قرار گرفته اند پاک شوند. متریک disk.busResets.summation مدت زمانی را اندازه گیری می کند که disk bus reset رخ داده باشد. این متریک در سطح VM و بصورت real time اندازه گیری می شود.اگر متریک disk.busResets.summation مقداری برای یک ماشین مجازی داشته باشد، این می تواند نشان دهنده مشکلات شدید مربوط به دیسک باشد. دیسک به دلایل زیر می تواند overload کند:
تعداد زیادی ماشین مجازی که به آن دیسک دسترسی دارند.
دستورات بسیاری زیادی که نشات گرفته از ماشین های مجازی هستند، به آن دیسک دسترسی دارند.
ماشین های مجازی با مقدار disk.busResets.summation که کند شده اند و احتمالا از کار هنگ یا crash کنند، ادمین با مشاهده ترافیک دیسک VM این مشکل را عیبیابی کنند تا ببینند آیا مشکلی در throughput هر یک از ماشینهای مجازی در دسترسی به دیسک وجود دارد یا خیر. به احتمال زیاد، شناسایی علت اصلی به کمک یک storage administrator نیاز دارد. حل این مشکل ممکن است نیاز به یک تعمیر سخت افزاری یا به طور معمول تر، Rebalance کردن ترافیک VM با انتقال ماشین های مجازی به دیگر datastore ها با ظرفیت بیشتر داشته باشد.
disk.commandsAborted.summation
مقدار در این متریک نشان می دهد که یک bottleneck در محیط مجازی وجود دارد. متریک disk.commandsAborted.summation تعداد دفعاتی که یک درخواست به دیسک ارسال شده و فرمان لغو شده است را نشان می دهد. این متریک در سطح VM بصورت real time اندازه گیری می شود. مقادیر این متریک برای هر VM باید صفر باشد. اگر مقدار چیزی جز صفر باشد، نشاندهنده یک مشکل جدی است و باید فورا بررسی شود و اگر آن را برطرف نکنید احتمالا VM ها هنگ و یا crash کنند.حل disk.commandsAborted.summation هم مثل disk.busResets.summation بالاتر توضیح دادیم، می باشد.
disk.totalLatency.average
مقدار در این متریک نشان می دهد که یک bottleneck در محیط مجازی وجود دارد. متریک disk.totalLatency.average میزان disk latency را که روی یک دیسک رخ می دهد را نشان می دهد. این متریک در سطح هاست و بصورت Real Time اندازه گیری می شود. Disk latency مدت زمانی است که به طول می انجامد تا یک پاسخ پس از تحویل پیام به دیسک ایجاد شود. این متریک برای ارزیابی اینکه آیا با مشکل performance مواجه هستیم یا نه مفید است زیرا اگر disk latency بالا باشد، در جایی مشکل وجود دارد.با این حال، از آنجایی که بسیاری از مسائل می توانند باعث تأخیر دیسک شوند، متریک disk.totalLatency.average دقیق نیست. بررسی بیشتر برای مشخص کردن مشکل دقیق ایجاد تاخیر ضروری است. دلایل احتمالی شامل مشکلات حافظه یا disk throughput است. ماشینهای مجازی که گرفتار مشکلات disk latency هستند، کند واکنش نشان میدهند.
Disk.totalLatency.average را می توان با load balancing یا با مشخص کردن منابع ماشینهای مجازی پرمصرف و اندازهگیری مناسب منابع یا انتقال آنها به سایر datastore ها رفع کرد.
disk.queueLatency.average
مقدار در این متریک نشان می دهد که یک bottleneck در محیط مجازی وجود دارد. متریک disk.queueLatency.average مدت زمانی را که یک فرمان در یک صف منتظر می ماند تا توسط دیسک پردازش شود را نشان می دهد. این متریک در سطح هاست بصورت Real Time اندازه گیری می شود. با افزایش زمان انتظار یک فرمان در صف، بدیهی است که Performance ماشین مجازی کاهش می یابد.یک مقدار بالای disk.queueLatency.average معمولا همراه با مقدار بالای disk.totalLatency.average است. زیرا به دلیل افزایش زمان برای پردازش یک فرمان توسط دیسک، احتمالاً دستورات در یک صف منتظر میمانند. بنابراین، اگر disk.queueLatency.average مشکلی را آشکار کرد، متریک disk.totalLatency.average نیز باید بررسی شود. اگر تأخیر دیسک واقعاً یک مشکل باشد، همانطور که در بخش disk.totalLatency.average ذکر شد، سایر performance bottleneck ها باعث این مشکل میشوند و بررسی کاملی در مورد متریک های مموری و throughput نیز باید انجام شود.
مانند مشکلات disk latency مشکلات disk.queueLatency.average را می توان با load balancing یا با مشخص کردن منابع ماشینهای مجازی پرمصرف و اندازهگیری مناسب منابع یا انتقال آنها به سایر datastore ها رفع کرد.
Throughput: an average of disk.read.average and disk.write.average
متریک disk.read.average میزان ترافیکی که از دیسک در دستورات read می آید را نشان می دهد و متریک disk.write.average به میزان ترافیکی که در دستورات write به دیسک می رود اشاره دارد. این مرتیک ها در سطح VM بصورت real-time اندازهگیری میشوند. میانگین با هم، disk.read.average و disk.write.average به اندازهگیری throughput دیسک تبدیل میشوند. Disk throughput به میانگین ظرفیت ترافیکی اشاره دارد که یک VM در اتصال خود به دیسک دارد.Throughput را می توان در طول زمان ترسیم کرد تا ببیند آیا ماشین مجازی در سطوح مختلف فعالیت دارای مشکلات Performance بوده یا خیر و آیا این افزایش امکان دارد با گرفتن پهنای باند روی دیسک باعث مشکلات Performance ای برای سایر VM ها شود. ماشینهای مجازی که با مشکلات throughput مواجه هستند یا روی هاست هایی هستند که throughput آنها محدود است، به کندی واکنش نشان میدهند. مهمتر از همه، سطوح بالای throughput به مشکلات disk latency اشاره می کند، و همچنین ممکن است علت مشکلات دیسک موارد دیگری مانند دستورات Aborted یا Bus Resets باشد. مشکل Throughput را می توان با rebalancing load یا انتقال VM ها حل کرد.
و در آخر به متریک های مربوط به Network در vmware esxi می پردازیم.
Network metrics
net.received.average, net.transmitted.average and net.usage.average
متریک های net.received.average، net.transmitted.average و net.usage.average ترافیک شبکه و استفاده مربوط به دستورات VM را اندازه گیری می کنند. این متریک ها در سطح VM اندازهگیری میشوند و مشابه اطلاعات جمعآوریشده در disk throughput هستند، اما disk throughput مستقیماً به ترافیکی که از دیتا استورها به سرور می رود، مربوط می شود. این متریک ها می توانند دید و View ای را در صورت استفاده از NFS storage یا ISCSI storage ارائه دهند، زیرا ارتباط بین سخت افزار data store در شبکه capture می شود.متریک های net.received.average، net.transmitted.average و net.usage.average مربوط به مناطقی هستند که معمولاً از نظر bottleneck ها بسیار کوچک هستند که مقادیر قابل توجهی را می توان فقط در سطح Cluster یا Data Center مشاهده کرد. با اینحال، در این سطوح net.received.average، net.transmitted.average و net.usage.average مقادیر ناچیزی از ترافیک را در مقایسه با سایر متریک نشان می دهد. متریک های شبکه بسیار به ندرت، یا هرگز، علت performance bottleneck هستند.


دسته بندی مطالب خوش آموز

نمایش دیدگاه ها (0 دیدگاه)
دیدگاه خود را ثبت کنید: