خوش آموز درخت تو گر بار دانش بگیرد، به زیر آوری چرخ نیلوفری را
Failover Cluster چیست؟

failover cluster به زبان ساده مجموعه ای از سرورها هستند که با هم کار می کنند تا high availability یا HA و دسترسی مستمر continuous availability را ارائه دهند. اگر به هر دلیلی یکی از سرورهای failover cluster خراب شده و از دسترس خارج شود، سرور دیگری که در Failover Cluster قرار دارد workload یا بار کاری را با حداقل یا بدون خرابی از طریق فرایندی که به آن failover گفته می شود بر عهده می گیرد.

برخی failover cluster ها فقط از سرورهای فیزیکی استفاده می کنند در حالی که برخی دیگر از ماشین های مجازی (VM) استفاده می کنند.
هدف اصلی یک failover cluster ارائه CA یا HA برای اپلیکیشن ها و سرویس ها است. cluster های CA همچنین با عنوان fault tolerant یا FT هم شناخته می شوند و به کاربران نهایی یا END User ها این امکان را می دهد که بدون وقفه از سرویس ها بهره ببرند. Cluster های HA ممکن است باعث وقفه کوتاهی در سرویس دهی به کاربران و مشتریان شود اما سیستم بدون از دست دادن داده و حداقل زمان خرابی به طور خودکار بازیابی می شود.
یک cluster از دو یا چند Node یا سرور تشکیل شده است که داده ها و نرم افزارها را برای پردازش از طریق کابل های فیزیکی یا یک شبکه امن اختصاصی منتقل می کند. سایر فناوری های Cluster را می توان برای load balancing، ذخیره سازی و پردازش همزمان یا موازی استفاده کرد. برخی از پیاده سازی های failover cluster را با فناوری clustering اضافی ترکیب می کنند.
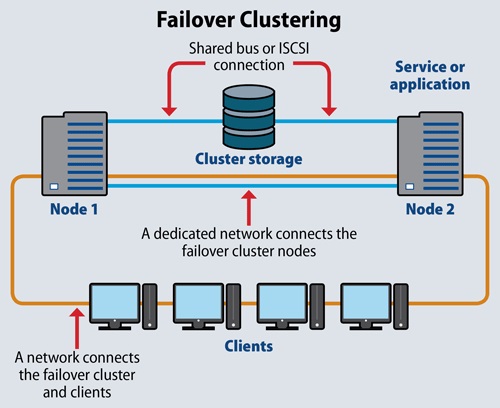
برای محافظت از اطلاعات شما، یک شبکه اختصاصی سرورهای failover cluster را به هم متصل می کند و CA و HA را ارائه می دهد.
در Cluster از نوع high availability گروهی از سرورهای مستقل، منابع و داده ها را در سراسر سیستم به اشتراک می گذارند. همه Node ها در یک failover cluster به فضای ذخیره سازی مشترک دسترسی دارند. Cluster های High availability همچنین شامل یک کانکشن مانیتورینگ هستند که سرورها برای بررسی heartbeat یا ضربان قلب یا سلامت دیگر سرورها از آن استفاده می کنند.
در یک پیکربندی ساده دو Node ای برای مثال، اگر node اول خراب شود، Node دوم از اتصال heartbeat برای تشخیص خرابی استفاده می کند و سپس خود را به عنوان Node فعال پیکربندی می کند. نرم افزار Clustering که بر روی هر node در خوشه نصب شده است اطمینان حاصل می کند که کلاینت ها به یک node فعال متصل می شوند.
برخی از نرم افزارهای cluster management، HA را برای ماشینهای مجازی (VM) فراهم می کند. در صورت وقوع خرابی، VM های روی هاست fail شده در هاست های دیگر ریستارت شده و بالا می آیند.
مورد دیگری که در صورت خرابی می تواد مشکل ایجاد کند، Shared storage است. گرچه با بهره گیری از تکنولوژی Raid مانند Raid 6 یا Raid 10 می توانید از وقوع خرابی های مربوط به storage ها جلوگیری کنید که حداقل تا خرابی دو هارد دیسک تحمل خرابی داشته باشد.
اگر همه سرورها به یک شبکه برق متصل شوند، برق می تواند نشان دهنده یک نقطه خرابی دیگر باشد. با تجهیز هر یک به UPS می توان از Node ها محافظت کرد.
بر خلاف مدل HA یک fault-tolerant cluster شامل چندین سیستم است که یک نسخه واحد از سيستم عامل را به اشتراک می گذارند. دستورات نرم افزاری که توسط یک سیستم مطرح می شود در سیستم های دیگر نیز اجرا می شود.
CA سازمان را ملزم به استفاده از تجهیزات کامپیوتری فرمت شده و یو پی اس ثانویه می کند. در یک CA failover cluster سیستم عامل دارای یک اینترفیس است که در آن یک برنامه نویس نرم افزار می تواند داده های مهم را در نقاط از پیش تعیین شده در یک transaction بررسی کند. CA تنها با استفاده از یک نسخه continuously available و تقریباً دقیق از یک ماشین فیزیکی یا مجازی که سرویس را اجرا می کند، به دست می آید. این نوع redundancy یا افزونگی 2N نامیده می شود.
سیستم های CA می توانند بسیاری از انواع مختلف خرابی را جبران کنند. یک سیستم fault tolerant می تواند به طور خودکار خرابی را تشخیص دهد.
نقطه failure یا خرابی را می توان بلافاصله شناسایی کرد و یک کامپوننت بک آپ می تواند فوراً و بدون وقفه در سرویس دهی را بر عهده بگیرد.
از نرم افزارهای Clustering می توان برای گروه بندی دو یا چند سرور به عنوان یک سرور مجازی استفاده کرد، یا می توانید بسیاری از تنظیمات دیگر CA failover را ایجاد کنید. به عنوان مثال، ممکن است یک Cluster طوری پیکربندی شود که در صورت خرابی یکی از سرورهای مجازی، بقیه با حذف موقت سرور مجازی خراب از Cluster، پاسخ دهند. سپس به طور خودکار Workload را بین سرورهای باقیمانده توزیع می کند تا زمانی که سرور Down شده آماده برای دوباره آنلاین شدن باشد.
یک جایگزین برای CA failover cluster ها استفاده از دابل سخت افزار سرور است که در آن تمام اجزای فیزیکی کپی می شوند. این سرورها به طور مستقل و همزمان روی سیستم های سخت افزاری جداگانه محاسبات را انجام می دهند. این سیستم های سخت افزاری با استفاده از یک Node اختصاصی که نتایج حاصل از هر دو سرور فیزیکی را مانیتور می کند، همگام سازی را انجام می دهند. این گزینه می تواند حتی گرانتر از سایر گزینه ها باشد. Stratus سازنده این سرورهای سخت افزاری با قابلیت FT، مدعی این است که زمان خرابی سیستم بیش از 32 ثانیه در سال نخواهد بود. با این حال ، هزینه یک سرور Stratus با CPU های dual برای هر ماژول synchronize شده تقریباً 160،000 دلار برای هر Node برآورد می شود.
دسترسی مداوم برای اپلیکیشن ها ماموریت مهم Failover Cluster
سیستم های Fault tolerant برای کامپیوترهایی که در online transaction processing یا OLTP استفاده می شوند یک ضرورت است. به عنوان مثال OLTP، که 100% در دسترس بودن را می طلبد، در سیستم های رزرو هواپیمایی، معاملات الکترونیکی سهام و ارز دیجیتال(کریپتوکارنسی) و بانکداری خودپرداز استفاده می شود. بسیاری دیگر از انواع سازمانها یا کسب و کارها(مانند مشاغل در زمینه های تولید، تدارکات و خرده فروشی) نیز از CA cluster یا از fault tolerant برای اپلیکیشن های مهم خود استفاده می کنند. برای برنامه ها و اپلیکیشن ها و همین طور سرویس هایی که به پنج تا 9 نیاز دارند HA Cluster ها به طور کلی، کافی و بس تلقی می شوند.
Database Replication
به گفته مایکروسافت، این شرکت در ابتدا Windows Server Failover Cluster (WSFC) را در ویندوز سرور 2016 برای محافظت از برنامه های مهم مانند پایگاه داده SQL Server و Microsoft Exchange معرفی کرد. سایر ارائه دهندگان پایگاه داده فناوری failover cluster را برای replication پایگاه داده ارائه می دهند. به عنوان مثال، MySQL Cluster دارای مکانیسم heartbeat برای تشخیص خرابی فوری، معمولاً در عرض یک ثانیه به سایر node های Cluster بدون وقفه سرویس دهی به مشتریان را ادامه می دهد. ویژگی geographic replication پایگاه داده ها را قادر می سازد تا در مکان های دورتر با هم Mirror شوند.
محصول دوم VMware vSphere HA است که با معرفی هاست های ESXI و VM ها در یک cluster، فرآیند خودکار failover را انجام می دهد.

برخی failover cluster ها فقط از سرورهای فیزیکی استفاده می کنند در حالی که برخی دیگر از ماشین های مجازی (VM) استفاده می کنند.
هدف اصلی یک failover cluster ارائه CA یا HA برای اپلیکیشن ها و سرویس ها است. cluster های CA همچنین با عنوان fault tolerant یا FT هم شناخته می شوند و به کاربران نهایی یا END User ها این امکان را می دهد که بدون وقفه از سرویس ها بهره ببرند. Cluster های HA ممکن است باعث وقفه کوتاهی در سرویس دهی به کاربران و مشتریان شود اما سیستم بدون از دست دادن داده و حداقل زمان خرابی به طور خودکار بازیابی می شود.
یک cluster از دو یا چند Node یا سرور تشکیل شده است که داده ها و نرم افزارها را برای پردازش از طریق کابل های فیزیکی یا یک شبکه امن اختصاصی منتقل می کند. سایر فناوری های Cluster را می توان برای load balancing، ذخیره سازی و پردازش همزمان یا موازی استفاده کرد. برخی از پیاده سازی های failover cluster را با فناوری clustering اضافی ترکیب می کنند.
برای محافظت از اطلاعات شما، یک شبکه اختصاصی سرورهای failover cluster را به هم متصل می کند و CA و HA را ارائه می دهد.
Failover Cluster ها چگونه کار می کنند؟
در حالی که failover cluster های CA برای 100% در دسترس بودن طراحی شده اند، HA cluster ها برای دسترسی 99.999 یا پنج تا 9 طراحی شده اند. این زمان در سال برابر 5 دقیقه و 26 ثانیه است. CA cluster ها دسترسی بیشتری را فراهم می کنند ولی برای پیاده سازی و اجرای آنها به سخت افزار بیشتر و نهایتا هزینه بیشتر نیاز است.High Availability Failover Clusters
در Cluster از نوع high availability گروهی از سرورهای مستقل، منابع و داده ها را در سراسر سیستم به اشتراک می گذارند. همه Node ها در یک failover cluster به فضای ذخیره سازی مشترک دسترسی دارند. Cluster های High availability همچنین شامل یک کانکشن مانیتورینگ هستند که سرورها برای بررسی heartbeat یا ضربان قلب یا سلامت دیگر سرورها از آن استفاده می کنند.در یک پیکربندی ساده دو Node ای برای مثال، اگر node اول خراب شود، Node دوم از اتصال heartbeat برای تشخیص خرابی استفاده می کند و سپس خود را به عنوان Node فعال پیکربندی می کند. نرم افزار Clustering که بر روی هر node در خوشه نصب شده است اطمینان حاصل می کند که کلاینت ها به یک node فعال متصل می شوند.
برخی از نرم افزارهای cluster management، HA را برای ماشینهای مجازی (VM) فراهم می کند. در صورت وقوع خرابی، VM های روی هاست fail شده در هاست های دیگر ریستارت شده و بالا می آیند.
مورد دیگری که در صورت خرابی می تواد مشکل ایجاد کند، Shared storage است. گرچه با بهره گیری از تکنولوژی Raid مانند Raid 6 یا Raid 10 می توانید از وقوع خرابی های مربوط به storage ها جلوگیری کنید که حداقل تا خرابی دو هارد دیسک تحمل خرابی داشته باشد.
اگر همه سرورها به یک شبکه برق متصل شوند، برق می تواند نشان دهنده یک نقطه خرابی دیگر باشد. با تجهیز هر یک به UPS می توان از Node ها محافظت کرد.
Continuous Availability Failover Clusters
بر خلاف مدل HA یک fault-tolerant cluster شامل چندین سیستم است که یک نسخه واحد از سيستم عامل را به اشتراک می گذارند. دستورات نرم افزاری که توسط یک سیستم مطرح می شود در سیستم های دیگر نیز اجرا می شود.CA سازمان را ملزم به استفاده از تجهیزات کامپیوتری فرمت شده و یو پی اس ثانویه می کند. در یک CA failover cluster سیستم عامل دارای یک اینترفیس است که در آن یک برنامه نویس نرم افزار می تواند داده های مهم را در نقاط از پیش تعیین شده در یک transaction بررسی کند. CA تنها با استفاده از یک نسخه continuously available و تقریباً دقیق از یک ماشین فیزیکی یا مجازی که سرویس را اجرا می کند، به دست می آید. این نوع redundancy یا افزونگی 2N نامیده می شود.
سیستم های CA می توانند بسیاری از انواع مختلف خرابی را جبران کنند. یک سیستم fault tolerant می تواند به طور خودکار خرابی را تشخیص دهد.
A hard drive
A computer processor unit
A I/O subsystem
A power supply
A network component
نقطه failure یا خرابی را می توان بلافاصله شناسایی کرد و یک کامپوننت بک آپ می تواند فوراً و بدون وقفه در سرویس دهی را بر عهده بگیرد.
از نرم افزارهای Clustering می توان برای گروه بندی دو یا چند سرور به عنوان یک سرور مجازی استفاده کرد، یا می توانید بسیاری از تنظیمات دیگر CA failover را ایجاد کنید. به عنوان مثال، ممکن است یک Cluster طوری پیکربندی شود که در صورت خرابی یکی از سرورهای مجازی، بقیه با حذف موقت سرور مجازی خراب از Cluster، پاسخ دهند. سپس به طور خودکار Workload را بین سرورهای باقیمانده توزیع می کند تا زمانی که سرور Down شده آماده برای دوباره آنلاین شدن باشد.
یک جایگزین برای CA failover cluster ها استفاده از دابل سخت افزار سرور است که در آن تمام اجزای فیزیکی کپی می شوند. این سرورها به طور مستقل و همزمان روی سیستم های سخت افزاری جداگانه محاسبات را انجام می دهند. این سیستم های سخت افزاری با استفاده از یک Node اختصاصی که نتایج حاصل از هر دو سرور فیزیکی را مانیتور می کند، همگام سازی را انجام می دهند. این گزینه می تواند حتی گرانتر از سایر گزینه ها باشد. Stratus سازنده این سرورهای سخت افزاری با قابلیت FT، مدعی این است که زمان خرابی سیستم بیش از 32 ثانیه در سال نخواهد بود. با این حال ، هزینه یک سرور Stratus با CPU های dual برای هر ماژول synchronize شده تقریباً 160،000 دلار برای هر Node برآورد می شود.
دسترسی مداوم برای اپلیکیشن ها ماموریت مهم Failover Cluster
سیستم های Fault tolerant برای کامپیوترهایی که در online transaction processing یا OLTP استفاده می شوند یک ضرورت است. به عنوان مثال OLTP، که 100% در دسترس بودن را می طلبد، در سیستم های رزرو هواپیمایی، معاملات الکترونیکی سهام و ارز دیجیتال(کریپتوکارنسی) و بانکداری خودپرداز استفاده می شود. بسیاری دیگر از انواع سازمانها یا کسب و کارها(مانند مشاغل در زمینه های تولید، تدارکات و خرده فروشی) نیز از CA cluster یا از fault tolerant برای اپلیکیشن های مهم خود استفاده می کنند. برای برنامه ها و اپلیکیشن ها و همین طور سرویس هایی که به پنج تا 9 نیاز دارند HA Cluster ها به طور کلی، کافی و بس تلقی می شوند.
Database Replication
به گفته مایکروسافت، این شرکت در ابتدا Windows Server Failover Cluster (WSFC) را در ویندوز سرور 2016 برای محافظت از برنامه های مهم مانند پایگاه داده SQL Server و Microsoft Exchange معرفی کرد. سایر ارائه دهندگان پایگاه داده فناوری failover cluster را برای replication پایگاه داده ارائه می دهند. به عنوان مثال، MySQL Cluster دارای مکانیسم heartbeat برای تشخیص خرابی فوری، معمولاً در عرض یک ثانیه به سایر node های Cluster بدون وقفه سرویس دهی به مشتریان را ادامه می دهد. ویژگی geographic replication پایگاه داده ها را قادر می سازد تا در مکان های دورتر با هم Mirror شوند.
انواع Failover Cluster
VMWare Failover Cluster
در میان محصولات مجازی سازی موجود، VMware چندین ابزار مجازی سازی برای VM cluster ارائه می دهد. vSphere vMotion یک معماری CA را ارائه می دهد که دقیقاً یک ماشین مجازی VMware و شبکه آن را بین شبکه های مرکز داده فیزیکی replicate یا توزیع می کند.محصول دوم VMware vSphere HA است که با معرفی هاست های ESXI و VM ها در یک cluster، فرآیند خودکار failover را انجام می دهد.
Windows Server Failover Cluster (WSFC)
شما می توانید با استفاده از WFSC سرورهای Hyper-V failover ایجاد کنید. این ویژگی در ویندوز 2016 و 2019 وجود دارد که cluster سرورهای فیزیکی را رصد کرده و در صورت نیاز Failover را ارائه می دهد. WFSC همچنین Role های clustering را که قبلاً به عنوان اپلیکیشن ها و سرویس های خوشه شده شناخته می شد را مانیتور می کند. WFSC شامل فناوری قبلی Cluster Shared Volume (CSV) مایکروسافت است تا یک فضای نامی توزیع شده(distributed namespace) برای دسترسی به ذخیره سازی مشترک از همه Node ها فراهم کند. علاوه بر این WSFC از ذخیره فایل CA برای SQL Server و VM های خوشه ای Hyper-V پشتیبانی می کند. همچنین از Role های HA که روی سرورهای فیزیکی و ماشین های مجازی Hyper-V اجرا می شوند پشتیبانی می کند.SQL Server Failover Clusters
در SQL Server 2017 مایکروسافت Always On را یک راه حل HA معرفی کرد که از WSFC به عنوان تکنولوژی پلتفرم استفاده می کند و کامپوننت های SQL Server را به عنوان منابع WSFC cluster ثبت می کند. به گفته مایکروسافت منابع مربوطه به عنوان یک نقش وابسته به سایر منابع WSFC ترکیب می شوند. WSFC سپس می تواند نیاز به ریستارت SQL Server instance را تشخیص داده و به طور خودکار آن را به یک Node دیگر منتقل کند.Red Hat Linux Failover Clusters
سازندگان سیستم عامل غیر مایکروسافتی هم فناوری های failover cluster خودشان را ارائه می دهند. به عنوان مثال، کاربران Red Hat Enterprise Linux (RHEL) می توانند HA failover cluster را با سیستم High Availability Add-On و Red Hat Global File System (GFS/GFS2 ایجاد کنند.

دسته بندی مطالب خوش آموز

نمایش دیدگاه ها (0 دیدگاه)
دیدگاه خود را ثبت کنید: