خوش آموز درخت تو گر بار دانش بگیرد، به زیر آوری چرخ نیلوفری را
متریک های دیسک برای مانیتورینگ در vmware vsphere
ماشینهای مجازی از فایلهای بزرگی (یا گروههایی از فایلها) به نام Virtual Disk یا دیسکهای مجازی (همچنین به نام فایلهای VMDK یا، Virtual Machine Disk file) برای ذخیره فایلهای سیستم عامل خود و برنامهها استفاده میکنند. ماشینهای مجازی بهطور پیشفرض با یک دیسک مجازی ایجاد میشوند، اما میتوانید آنها را طوری پیکربندی کنید که تعداد بیشتری Virtual disk داشته باشند. دیسکهای مجازی در datastore ها قرار دارند که بسته به پیکربندی، میتوانند در مکانهای ذخیرهسازی مشترک مختلفی قرار گیرند.

VSphere گزارش disk I/O و متریک های ظرفیت را در سطوح مختلف از جمله دیتااستورها، ماشینهای مجازی و هاست های ESXi را می دهد. از آنجایی که چندین هاست و ماشین مجازی میتوانند دیتا استورها را به صورت Shared استفاده کنند، مانیتورینگ در سطح datastore به شما disk performance را نشان دهد. با این حال، برای ردیابی سلامت یک ماشین مجازی یا هاست خاص، اطمینان حاصل کنید که Performance دیسکهای مجازی (یعنی آنچه سیستم عامل مهمان شما در اختیار دارد) و دیسکهای فیزیکی (یعنی آنچه هاست شما روی آن بوده) را مانیتورینگ کنید. ردیابی متریک های دیسک در هر یک از این سطوح میتواند به ارائه تصویر کاملتری از سلامت کلاستر و عیبیابی در مواردی که مشکلات رخ میدهد کمک کند.
VM ها از storage controller ها برای دسترسی به دیسک های مجازی در یک دیتا استور استفاده می کنند. Storage controller ها به vm ها اجازه ارسال دستور روی هاست های Esxi ای که روی آن در حال اجرا هستند را می دهد و سپس آن دستورات را به دیسک مجازی مناسب هدایت میکند. از آنجایی که ماشینهای مجازی دستورات را از طریق هاست های ESXi به datastore ها ارسال میکنند، متریک های مانیتورینگ که دیدی در مورد throughput و تأخیر ارائه میدهند و میتواند به شما کمک کند تا اطمینان حاصل کنید که هاستها و ماشینهای مجازی قادر به دسترسی موثر و بدون وقفه بهstorage فیزیکی هستند.


اگردیدید که در total latency مشکلی دارید میتوانید میانگین average latency برای read که disk.readLatency.avg است و برای Write که disk.writeLatency.avg می باشد را بررسی کنید تا تعیین کنید که آیا یکی یا دیگری در تأخیر کلی تأثیر بیشتری دارد یا خیر. به طور مشابه، میتوانید تأخیرهای read و Write را در سطح VM، هاست و datastore تجزیه کنید تا تعیین کنید که چه چیزهای افزایش تأخیر کل نقش دارند.
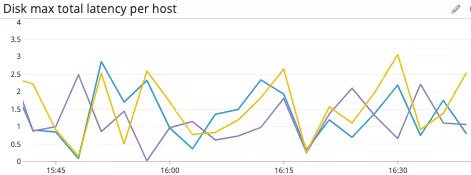
high disk latency با سایر متریک هایresource usage می تواند در تعیین اینکه آیا علت اصلی کمبود رم یا CPU در دسترس است یا نه، مفید باشد. در این صورت، میتوانید تشخیص دهید که کدام ماشینهای مجازی روی هاست یا کلاستر شما بیشترین مصرف منابع را دارند و یا باید منابع بیشتری را به آن ماشینها تخصیص دهید یا آنها را به دیتااستورها با ظرفیت بیشتر منتقل کنید.
برای درک بهتر Performance محیط خود، تأخیر صف را در کنار disk.usage.avg مانیتور کنید. برای مثال، میتوانید مشخص کنید که آیا افزایش تأخیر صف مربوط به کاهش کلی در throughput است یا خیر. برای مثال، میتوانید تعیین کنید که آیا افزایشqueue latency مربوط به کاهش کلی در throughput است یا خیر. به طور مشابه، می توانید ببینید که آیا افزایش throughput قبل از افزایش تاخیر در صف بوده است، زیرا دیتااستور شما قادر به پردازش افزایش فشار نبوده است.
مانند total latency ، تأخیر صف را میتوان با انتقال ماشینهای مجازی به دیتا استور با ظرفیت دیسک بیشتر، افزایشqueue depth دیتااستور یا فعال کردن storage I/O control یا SIOC حل کرد.

VSphere گزارش disk I/O و متریک های ظرفیت را در سطوح مختلف از جمله دیتااستورها، ماشینهای مجازی و هاست های ESXi را می دهد. از آنجایی که چندین هاست و ماشین مجازی میتوانند دیتا استورها را به صورت Shared استفاده کنند، مانیتورینگ در سطح datastore به شما disk performance را نشان دهد. با این حال، برای ردیابی سلامت یک ماشین مجازی یا هاست خاص، اطمینان حاصل کنید که Performance دیسکهای مجازی (یعنی آنچه سیستم عامل مهمان شما در اختیار دارد) و دیسکهای فیزیکی (یعنی آنچه هاست شما روی آن بوده) را مانیتورینگ کنید. ردیابی متریک های دیسک در هر یک از این سطوح میتواند به ارائه تصویر کاملتری از سلامت کلاستر و عیبیابی در مواردی که مشکلات رخ میدهد کمک کند.
VM ها از storage controller ها برای دسترسی به دیسک های مجازی در یک دیتا استور استفاده می کنند. Storage controller ها به vm ها اجازه ارسال دستور روی هاست های Esxi ای که روی آن در حال اجرا هستند را می دهد و سپس آن دستورات را به دیسک مجازی مناسب هدایت میکند. از آنجایی که ماشینهای مجازی دستورات را از طریق هاست های ESXi به datastore ها ارسال میکنند، متریک های مانیتورینگ که دیدی در مورد throughput و تأخیر ارائه میدهند و میتواند به شما کمک کند تا اطمینان حاصل کنید که هاستها و ماشینهای مجازی قادر به دسترسی موثر و بدون وقفه بهstorage فیزیکی هستند.
Metric to alert on: Disk commands aborted
در vSphere، یکstorage device شایدdatastore هایی را در خود جای دهد که به بسیاری از ماشینهای مجازی سرویس می دهند. اگر دستورات ماشینهای مجازی به سختافزار storage که در آنdatastore ها قرار دارند افزایش یابد، شاید حافظه overload کرده و پاسخگو نباشد. اگر این اتفاق رخ دهد، هاست ESXi که آن دستورات را ارسال کرده است، آنها را لغو یاabort می کند. از آنجایی که دستوراتabort شده میتوانند باعث کندی Performance ماشینهای مجازی و حتی خرابی شوند، متریک disk.commandsAborted باید همیشه روی صفر باقی بماند. اگر یک هاست ESXi شروع به abort کردن دستورات کرد، و شما تشخیص دادید که دلیل آن ترافیک بالای فرمان VM به دیتا استور است، میتوانید ماشینهای مجازی را به lun های دیگری منتقل کنید تا از ارسال همه درخواستها به یک دیتا استور اجتناب کنید.Metric to alert on: Disk bus resets
در یک storage با دستورات خواندن و نوشتن بیش از حد از یک هاست ESXi محصور شود، یا اگر با مشکل سختافزاری مواجه شود و دستورات را لغو نکند، تمام دستورات منتظر در صف خود را پاک میکند که بدان disk bus reset گفته می شود. Disk bus resets نشانهای ازbottleneck ذخیرهسازی دیسک است و میتواند باعث کندی Performance ماشین مجازی شود، زیرا ماشینهای مجازی باید دوباره آن درخواستها را ارسال کنند. Disk bus resets معمولاً در محیطهای vSphere سالم اتفاق نمیافتد و همیشه این مقدار باید 0 باشد. برای حل این مشکل، ادمین ها شاید نیاز به استفاده از Storage vMotion برای توزیع ماشینهای مجازی و دیسکهای مجازی در datastore های مختلف داشته باشند تا Performance را بهینه کنند.Metrics to alert on: Datastore provisioned capacity and actual VM usage
Storage منبعی محدود است متریک diskspace.provisioned.latest میزان فضای ذخیرهسازی موجود در دیتا استورهایی را که هاست ESXi با آنها ارتباط برقرار میکند، ردیابی میکند، در حالی که virtualDisk.actualUsage به شما امکان میدهد تا میزان فضای دیسک را که ماشینهای مجازی در حال اجرا بر روی آن هاست به طور فعال استفاده میکنند را مانیتورینگ کنید. همبستگی این متریک ها می تواند به شما کمک کند تا در صورتی که فضای دیسک مناسبی را برای آنچه ماشین های مجازی نیاز دارند، مانیتورینگ کنید. استفاده تقریبا تمام دیسک دیتا استور می تواند باعث ایجاد خطاهای کمبود فضا و کاهش Performance ماشین مجازی شود. برای جلوگیری از این امر، میتوانید زمانی که VM usage از ظرفیت استوریج provision شده بیش از حد (مثلاً بیش از 85 درصد) میشود، یک هشدار تنظیم کنید. اگر ظرفیت ذخیرهسازی داده نزدیک به ظرفیت مشخص شده هشدار است، ظرفیت آن را افزایش دهید، ماشینهای مجازی را به دیتا استور دیگری منتقل کنید، یا ماشینهای مجازی غیرفعال را حذف کنید تا فضا آزاد شود.Metric to watch: Disk latency
مانیتورینگ latency کلیدی است برای اطمینان از اینکه ماشین های مجازی شما به طور مؤثر و بدون تأخیر با دیسک های مجازی خود ارتباط برقرار می کنند. Total disk latency مدت زمان، بر حسب میلی ثانیه، که به طول می انجامد تا یک هاست ESXi برای پردازش درخواست ارسال شده از یک VM به یک دیتا استور را اندازه گیری می کند. ماینتورینگ total disk latency می تواند به شما کمک کند تا تعیین کنید آیا vSphere مطابق انتظار عمل می کند یا خیر.اگردیدید که در total latency مشکلی دارید میتوانید میانگین average latency برای read که disk.readLatency.avg است و برای Write که disk.writeLatency.avg می باشد را بررسی کنید تا تعیین کنید که آیا یکی یا دیگری در تأخیر کلی تأثیر بیشتری دارد یا خیر. به طور مشابه، میتوانید تأخیرهای read و Write را در سطح VM، هاست و datastore تجزیه کنید تا تعیین کنید که چه چیزهای افزایش تأخیر کل نقش دارند.
high disk latency با سایر متریک هایresource usage می تواند در تعیین اینکه آیا علت اصلی کمبود رم یا CPU در دسترس است یا نه، مفید باشد. در این صورت، میتوانید تشخیص دهید که کدام ماشینهای مجازی روی هاست یا کلاستر شما بیشترین مصرف منابع را دارند و یا باید منابع بیشتری را به آن ماشینها تخصیص دهید یا آنها را به دیتااستورها با ظرفیت بیشتر منتقل کنید.
Metric to watch: Queue latency
بسته به پیکربندی، دستگاههایstorage مانند LUN تعداد محدودی دستور دارند که میتوانند در هر زمان در صف قرار دهند. هنگامی که حجم دستورات ماشین مجازی ارسال شده از یک هاست ESXi بیشتر از مقداری باشد که یک دستگاه ذخیره سازی می تواند در صف قرار دهد، آن دستورات در VMKernel شروع به صف می کنند. متریک disk.queueLatency میانگین زمانی را که VM دستور میدهد تا در صف VMkernel قرار گیرد را ردیابی میکند. هر چه یک فرمان بیشتر در یک صف منتظر بماند تا توسط دیسک پردازش شود، ماشین مجازی که آن فرمان را ارسال کرده بدتر عمل می کند. تاخیر بالا در صف ارتباط نزدیکی باtotal latency بالا دارد زیرا دستورات معمولاً باید در یک صف منتظر بمانند.برای درک بهتر Performance محیط خود، تأخیر صف را در کنار disk.usage.avg مانیتور کنید. برای مثال، میتوانید مشخص کنید که آیا افزایش تأخیر صف مربوط به کاهش کلی در throughput است یا خیر. برای مثال، میتوانید تعیین کنید که آیا افزایشqueue latency مربوط به کاهش کلی در throughput است یا خیر. به طور مشابه، می توانید ببینید که آیا افزایش throughput قبل از افزایش تاخیر در صف بوده است، زیرا دیتااستور شما قادر به پردازش افزایش فشار نبوده است.
مانند total latency ، تأخیر صف را میتوان با انتقال ماشینهای مجازی به دیتا استور با ظرفیت دیسک بیشتر، افزایشqueue depth دیتااستور یا فعال کردن storage I/O control یا SIOC حل کرد.
Metric to watch: Disk throughput
برای اطمینان از اینکه دیتااستورها، هاست های ESXi و ماشین های مجازی شما دستورات Read و write را بدون وقفه پردازش می کنند،I/O throughput آنها را برای مشاهدهactivity آن ها زیر نظر بگیرید. مانیتورینگ throughput در سطوح مختلف و ارتباط آن با سایر متریک می تواند به شما در شناساییbottleneck و تعیین دقیق محل وقوع یک مشکل کمک کند.

دسته بندی مطالب خوش آموز

نمایش دیدگاه ها (0 دیدگاه)
دیدگاه خود را ثبت کنید: